Лесные пожары в Красноярском крае
пример моделирования географически распределенных данных методами машинного обучения
Мы рассмотрим некоторые возможности экосистемы языка программирования R в применении к анализу данных по лесным пожарам. Базовый подход к исследованию термоточек в Российской Федерации был ранее разобран в одной из предыдущих записей в блоге. Цель настоящей публикации – выявить тенденции с пожарами в Красноярском крае за период 2011-2020 года и построить пример модели машинного обучения для классификации пожаров находящихся в критической, с точки зрения вероятности возникновения пожаров, зоне менее 5 км от населенных пунктов. Отметим что используемые подходы могут быть легко распространены и на другие регионы РФ. Данные, использованные здесь, были собраны Федеральным агентством лесного хозяйства ФБУ «Авиалесоохрана» и предоставлены Информационной системой дистанционного мониторинга Федерального агентства лесного хозяйства (ИСДМ-Рослесхоз).
Язык R изначально задумывался авторами как статистический язык программирования, но сейчас, в силу наличия огромного количества библиотек, расширяющих базовые возможности языка, и доступности, используется для самых различных задач и хорошо зарекомендовал себя в применении к геовычислениям (см., например, монографию Geocomputation with R или материалы курсов Визуализация и анализ географических данных на языке R и Пространственная статистика и моделирование на языке R). Хорошей альтернативой для использования современных методов программирования в применении к геовычислениям является язык программирования Python (см. Geoprocessing with Python).
Основой для построения модели машинного обучения в нашем случае является библиотека tidymodels. Для геосамплинга (повторной выборки географически распределенных данных) мы используем экспериментальную библиотеку spatialsample как в статьях Spatial resampling for #TidyTuesday and the #30DayMapChallenge и Predicting injuries for Chicago traffic crashes, авторами которых является Julia Silge. Моделям машинного обучения в применении к пожарам посвящено очень много различных публикаций, однако модели такого рода в них ранее не рассматривались. Большой обзор A review of machine learning applications in wildfire science and management является, по сути, энциклопедией возможных подходов к задачам моделирования в области изучения лесных пожаров и может служить отправной точкой для исследователей.
Разведочный анализ данных
Загрузим необходимые библиотеки.
library(tidyverse)
library(tidymodels)
library(magrittr)
library(kableExtra)Приведем пример таблицы данных.
wildfires %>%
head(., 10) %>%
kbl() %>%
kable_paper("hover", full_width = F)| Lon | Lat | Dist | Sdate | StateNY0 | Place | Earea | TypeForest | Comment | year | month | fire_duration |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 83.47389 | 67.71389 | 100.2 | 2012-03-18 | 2012-03-28 | Туруханское | 25 | NA | NA | 2012 | мар | 10 days |
| 94.60806 | 55.17389 | 5.2 | 2012-03-29 | 2012-04-08 | Саянское | 260 | Сельхозвыжигания | В земфонде | 2012 | мар | 10 days |
| 83.48389 | 67.71611 | 100.4 | 2012-03-30 | 2012-04-15 | Туруханское | 274 | NA | NA | 2012 | мар | 16 days |
| 91.45306 | 53.76389 | 3.7 | 2012-03-31 | 2012-04-10 | Боградское | 3 | NA | NA | 2012 | мар | 10 days |
| 91.52389 | 53.84111 | 9.1 | 2012-04-01 | 2012-04-12 | Минусинское | 97 | NA | NA | 2012 | апр | 11 days |
| 91.72389 | 53.17611 | 3.9 | 2012-04-04 | 2012-04-14 | Саяно-Шушенское | 20 | Не лесфонд | Болото среди земфонда | 2012 | апр | 10 days |
| 91.89194 | 53.27195 | 2.8 | 2012-04-04 | 2012-04-14 | Шушенский Бор НП | 28 | NA | NA | 2012 | апр | 10 days |
| 83.48389 | 67.71611 | 100.4 | 2011-03-26 | 2011-04-05 | Туруханское | 81 | NA | NA | 2011 | мар | 10 days |
| 92.76195 | 56.10389 | 1.7 | 2011-04-02 | 2011-04-12 | Красноярское | 64 | NA | NA | 2011 | апр | 10 days |
| 92.83195 | 53.26805 | 0.5 | 2011-04-09 | 2011-04-19 | Каратузское | 39 | Сельхозвыжигания | По данным лесничества | 2011 | апр | 10 days |
Выделим переменные для анализа:
Lon,Lat– географические координатыDist– удаление от ближайшего населенного пунктаSdate– дата первого наблюденияStateNY0– дата ликвидацииPlace– лесничествоEarea– площадь, пройденная огнем в субъекте РФ, га (всего)TypeForest– тип термоточкиComment– комментарийyear,month– год и месяцfire_duration– длительность горения
Набор исторических данных по лесным пожарам данных включает в себя всего 29 388 наблюдений, временной диапазон: с 2011 года по 2020 год. Наибольший интерес для исследования представляет географическое распределение пожаров и их динамика с течением времени. Отобразим термоточки на карте Красноярского края, для чего сначала загрузим несколько типов карт-подложек, предварительно определив их границы.
library(ggmap)
KRSK <- c(left = 80, bottom = 50, right = 115, top = 78)
half_KRSK <- c(left = 82, bottom = 50, right = 110, top = 66.34)
quater_KRSK <- c(left = 86.5, bottom = 51.5, right = 103, top = 59)
map <- get_stamenmap(KRSK, zoom = 6, maptype = "toner-background")
half_map <- get_stamenmap(half_KRSK, zoom = 6, maptype = "toner-background")
quater_map <- get_stamenmap(quater_KRSK, zoom = 6, maptype = "toner-background")ggmap(map) +
geom_point(data = wildfires %>%
dplyr::select(Lon, Lat, Earea, year) %>% na.omit(),
alpha = 0.025,
aes(Lon, Lat,
size = Earea/1000),
color = "red"
) + silgelib::theme_plex() +
guides(color = guide_legend(nrow = 2,
override.aes = list(alpha = 1, size = 4)),
size = guide_legend(override.aes = list(alpha = 1))) +
labs(x = "", y = "", size = "площадь пожара, тыс. га:", color = "год:") +
theme(legend.position = "bottom", legend.box = "vertical",
axis.title.x=element_blank(),
axis.text.x=element_blank(),
axis.ticks.x=element_blank(),
axis.title.y=element_blank(),
axis.text.y=element_blank(),
axis.ticks.y=element_blank()
) 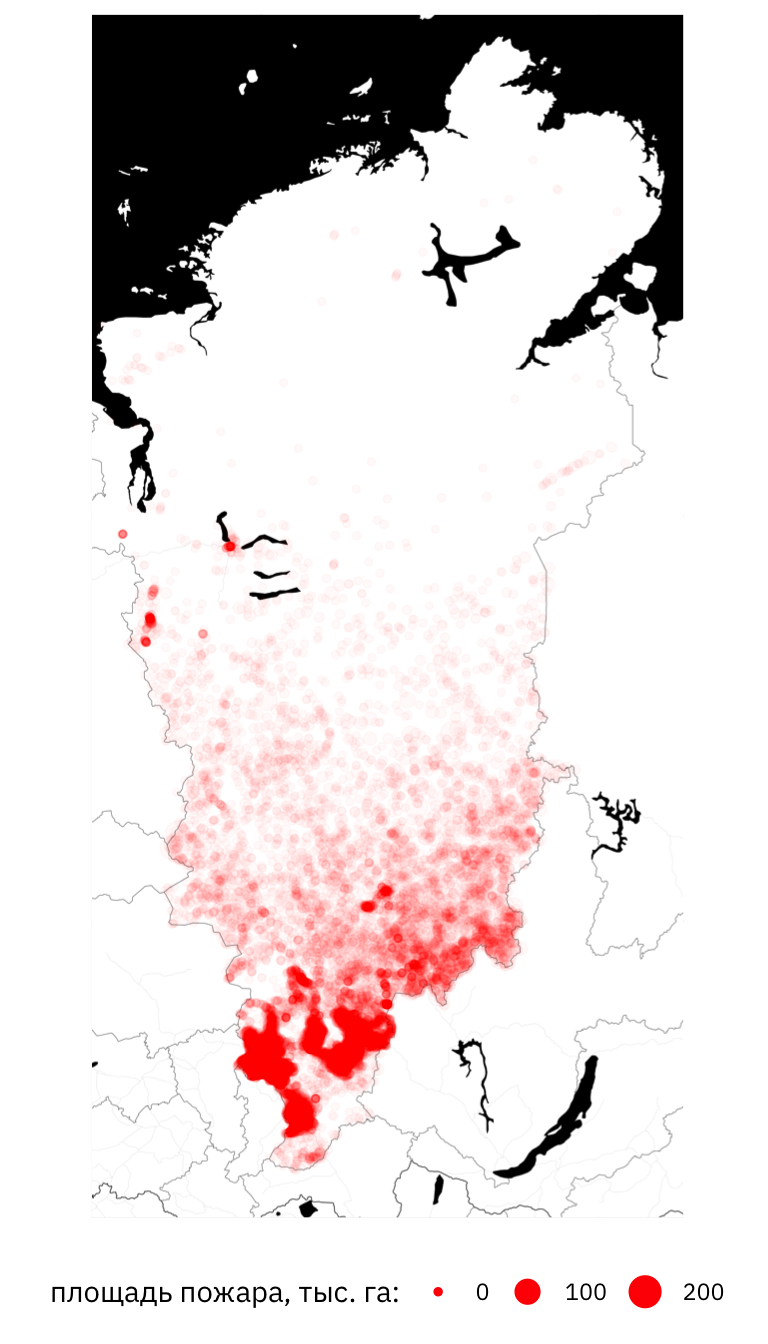
Рисунок 1: Карта пожаров Красноярского края в 2011-2020 годах. Размер точки пропорционален площади пожара
Нетрудно видеть, как распределены пожары в зависимости от сезона.
wildfires <-
wildfires %>%
mutate(
season = case_when(
month %in% c("дек", "янв", "фев") ~ "зима",
month %in% c("мар", "апр", "май") ~ "весна",
month %in% c("июн", "июл", "авг") ~ "лето",
month %in% c("сен", "окт", "ноя") ~ "осень"
)
) %>%
mutate(season = factor(season, levels = c("зима", "весна", "лето", "осень"))) ggmap(map) +
geom_point(data = wildfires %>%
dplyr::select(Lon, Lat, Earea, year, season) %>% na.omit(),
alpha = 0.05,
aes(Lon, Lat,
size = Earea/1000, color = season)
) + silgelib::theme_plex() +
guides(color = guide_legend(nrow = 1,
override.aes = list(alpha = 1, size = 4)),
size = guide_legend(override.aes = list(alpha = 1))) +
#labs(x = "", y = "", size = "площадь пожара, тыс. га:", color = "сезон:") +
theme(legend.position = "none", legend.box = "vertical",
axis.title.x=element_blank(),
axis.text.x=element_blank(),
axis.ticks.x=element_blank(),
axis.title.y=element_blank(),
axis.text.y=element_blank(),
axis.ticks.y=element_blank()
) +
facet_wrap(~season, nrow = 1)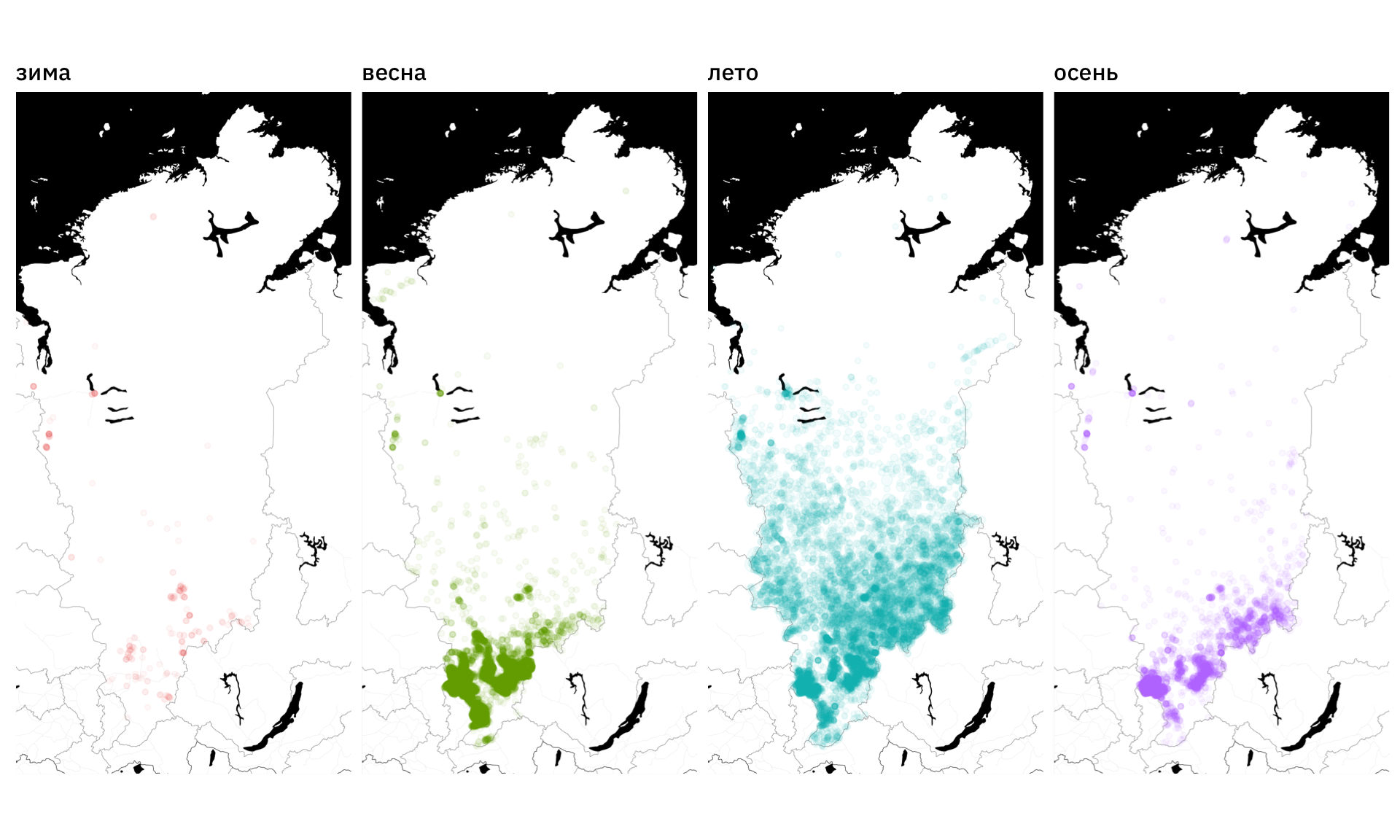
Рисунок 2: Карта пожаров Красноярского края в 2011-2020 годах в зависимости от сезона
Красноярский край является одним из самых протяженных регионов Российской Федерации, часть края находится за пределами Северного полярного круга. Количество пожаров, произошедших за 2011-2020 года севернее полярного круга составило чуть более 3%, поэтому мы будем в основном работать с пожарами, которые произошли на юге края. Предыдущий рисунок, к сожалению, не визуализирует интенсивность пожаров, один из хороших способов выявить локальные максимумы – карта плотности пожаров, показанная на рисунке ниже. Актуальные данные по населенным пунктам были получены с сайта ИНИД.
cities_KRSK_krai <-
cities_large_set %>%
filter(region == "Красноярский край")
ewbrks <- seq(90,100,5)
nsbrks <- seq(52,60,2)
ewlbls <- unlist(lapply(ewbrks, function(x) ifelse(x > 0, paste(x, "°E"), ifelse(x < 0, paste(x, "°W"),x))))
nslbls <- unlist(lapply(nsbrks, function(x) ifelse(x < 0, paste(x, "°S"), ifelse(x > 0, paste(x, "°N"),x))))
for_text <- arrange(cities_KRSK_krai, -population) %>% head(., 6)
library(ggrepel)
set.seed(2021)
ggmap(quater_map) +
stat_density_2d(data = wildfires %>%
rename(lon = Lon, lat = Lat) %>%
dplyr::filter(lat < 66.34),
aes(fill = stat(nlevel)),
geom = "polygon",
n = 200, bins = 20, contour = TRUE, alpha = 0.3) +
silgelib::theme_plex() +
scale_x_continuous(breaks = ewbrks, labels = ewlbls, limits = c(86.5, 103)) +
scale_y_continuous(breaks = nsbrks, labels = nslbls, limits = c(51.5, 59)) +
theme(legend.position = "none") +
viridis::scale_fill_viridis(option = "inferno") +
geom_point(data = cities_KRSK_krai, aes(longitude_dd, latitude_dd, size = population),
alpha = 0.6, color = "black") +
ggrepel::geom_text_repel(data = for_text, face = "bold",
aes(longitude_dd, latitude_dd, label = settlement), bg.color = "white",
bg.r = 0.25,alpha = 0.8,
min.segment.length = 0, max.segment.length = Inf, box.padding = 4, size = 5) +
scale_size(range = c(0, 10)) +
labs(x = "", y = "")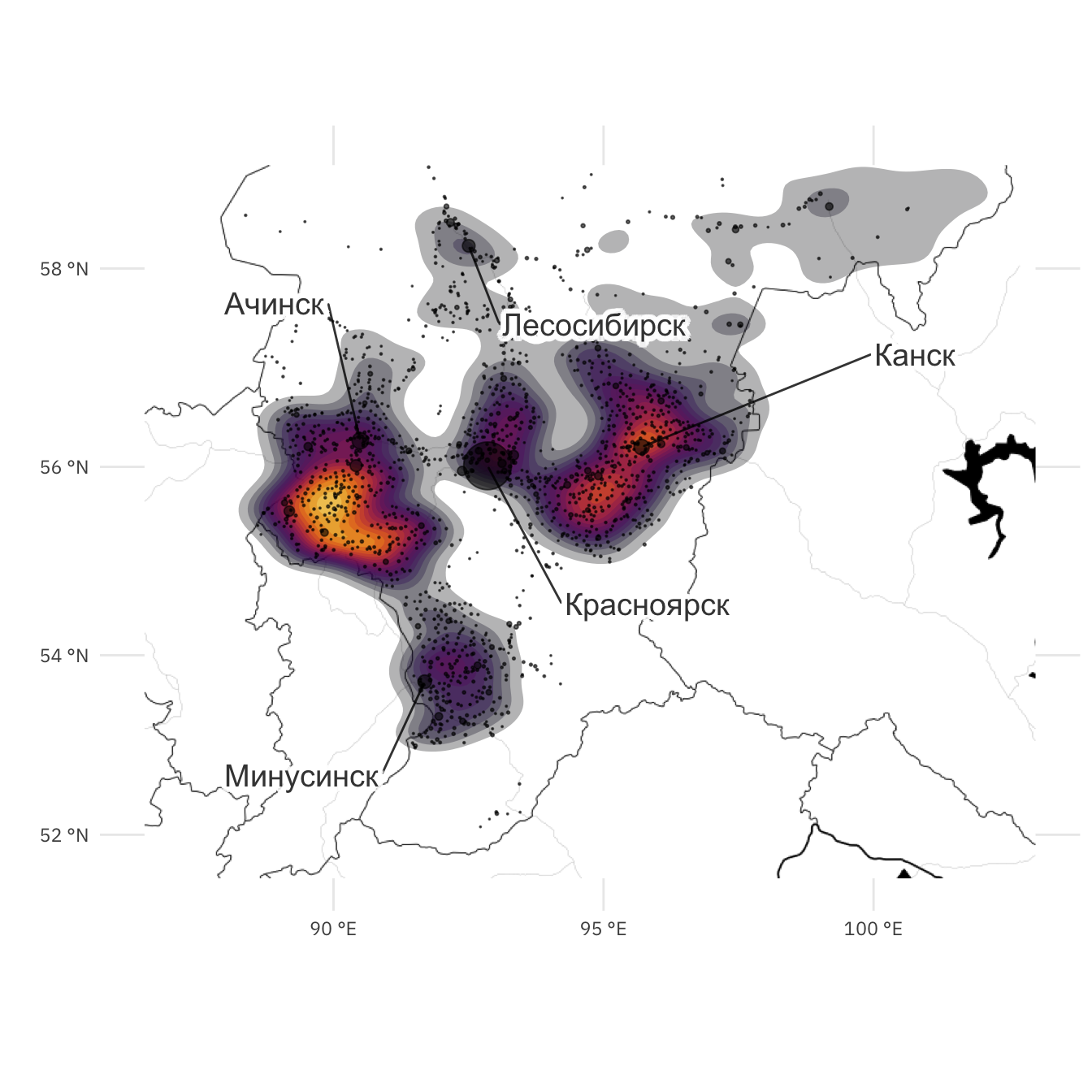
Рисунок 3: Карта пожаров южных районов Красноярского края в 2011-2020 годах. Цветом показаны районы с максимальной плотностью пожаров (светелее – больше). Точки черного цвета соответствуют населенным пунктам края, размер точек пропорционален количеству населения
На рисунке хорошо видно, что пожары в южных районах края в основном происходили вблизи населенных пунктов, что подтверждает антропогенное влияние деятельности человека на пожары. Небольшое исследование данных показывает, что локальные максимумы плотности пожаров соответствуют: первый максимум 55°58′93″ с.ш., 90°04′23″ в.д., в районе которого находятся населенные пункты п. Красная Сопка и с. Крутояр; второй максимум имеет координаты 56°26′83″ с.ш., 95°65′61″ в.д. (пик второго максимума в 1,4 раза меньше первого), где находятся г. Канск, с. Филимоново, с. Чечеул.
Исследуем вариацию пожаров в зависимости от года. На следующем рисунке можно хорошо проследить, что пожары с большой площадью более 10 000 га за период с 2011 по 2020 год сместились от западной к восточной границе Красноярского края.
ewbrks <- seq(85,110,10)
nsbrks <- seq(50,70,4)
ewlbls <- unlist(lapply(ewbrks, function(x) ifelse(x > 0, paste(x, "°E"), ifelse(x < 0, paste(x, "°W"),x))))
nslbls <- unlist(lapply(nsbrks, function(x) ifelse(x < 0, paste(x, "°S"), ifelse(x > 0, paste(x, "°N"),x))))
ggmap(half_map) +
geom_point(data = wildfires %>% dplyr::filter(Earea > 10000) %>%
dplyr::select(Lon, Lat, Earea, year) %>% na.omit(),
alpha = 0.8,
aes(Lon, Lat,
size = Earea/1000,
color = factor(year))
) +
silgelib::theme_plex() +
scale_x_continuous(breaks = ewbrks, labels = ewlbls, limits = c(85, 107)) +
scale_y_continuous(breaks = nsbrks, labels = nslbls, limits = c(51.5, 65)) +
guides(size = guide_legend(override.aes = list(alpha = 1)),
color = guide_legend(nrow = 2, override.aes = list(alpha = 1, size = 4))) +
viridis::scale_color_viridis(discrete = T, option = "cividis") +
labs(size = "площадь пожара, тыс. га:", x = "", y = "", color = "год:") +
theme(legend.position = "bottom", legend.box = "vertical") +
guides(size = guide_legend(order = 1))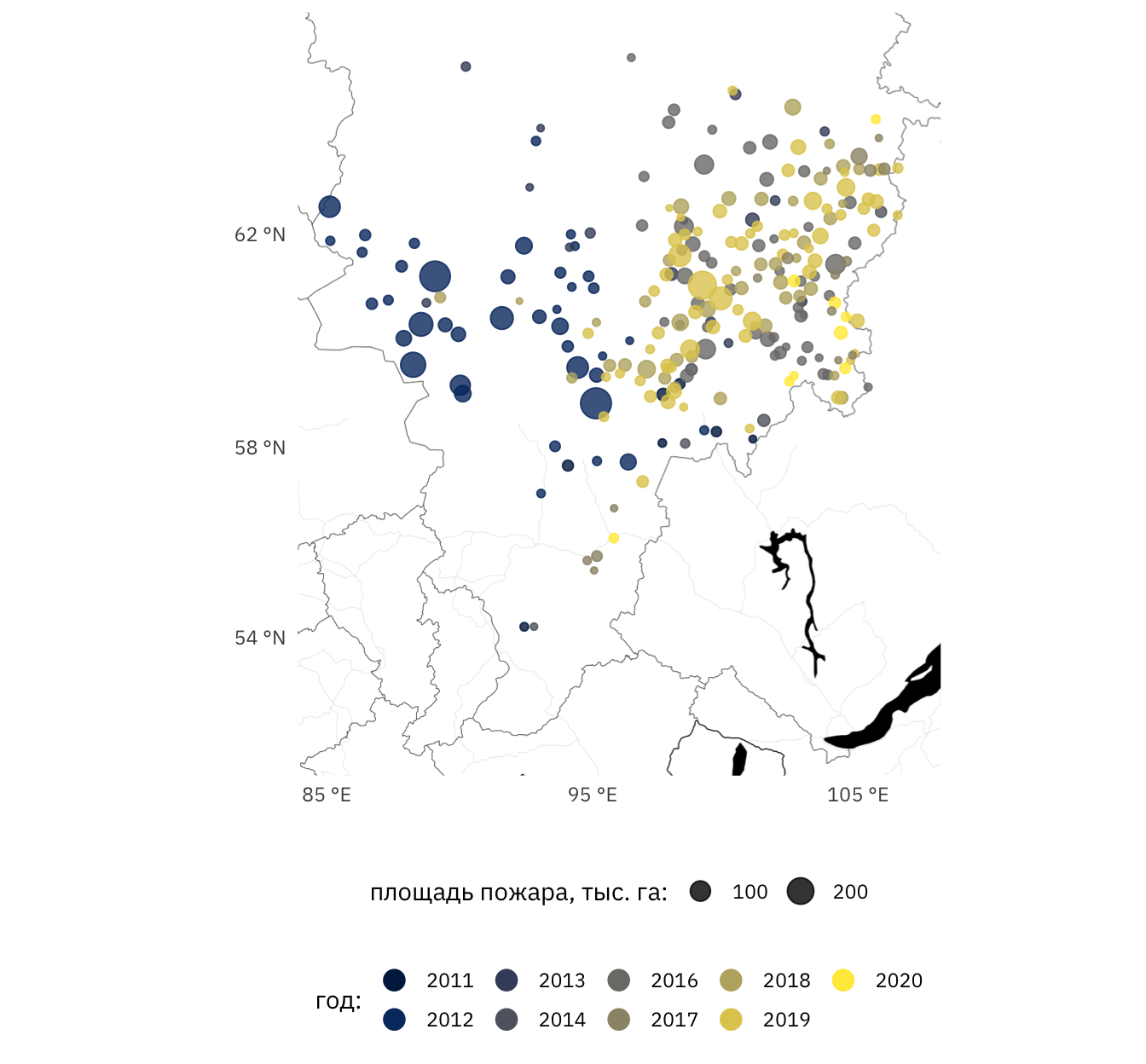
Рисунок 4: Пожары площадью свыше 10 000 га в Красноярском крае в 2011-2020 годах. Размер точки пропорционален площади пожара, цвет соответствует году (темнее – старше)
Смещение крупных пожаров к восточной границе края имеет глобальный характер, что отмечалось, например, в работе Результаты и перспективы спутникового мониторинга природных пожаров Сибири. Аналогичный характер вариации прослеживается и для относительно небольших пожарах.
ewbrks <- seq(85,110,10)
nsbrks <- seq(50,70,4)
ewlbls <- unlist(lapply(ewbrks, function(x) ifelse(x > 0, paste(x, "°E"), ifelse(x < 0, paste(x, "°W"),x))))
nslbls <- unlist(lapply(nsbrks, function(x) ifelse(x < 0, paste(x, "°S"), ifelse(x > 0, paste(x, "°N"),x))))
ggmap(half_map) +
geom_point(data = wildfires %>%
dplyr::filter(Earea < 1000) %>%
dplyr::select(Lon, Lat, Earea, year) %>% na.omit(),
alpha = 0.3,
aes(Lon, Lat,
size = Earea,
color = factor(year))
) +
silgelib::theme_plex() +
scale_x_continuous(breaks = ewbrks, labels = ewlbls, limits = c(85, 107)) +
scale_y_continuous(breaks = nsbrks, labels = nslbls, limits = c(51.5, 66)) +
scale_size(range = c(0, 4.5)) +
guides(color = guide_legend(nrow = 2,
override.aes = list(alpha = 1, size = 4)),
size = guide_legend(override.aes = list(alpha = 1))) +
viridis::scale_color_viridis(discrete = T, option = "cividis") +
labs(x = "", y = "", size = "площадь пожара, га:", color = "год:") +
theme(legend.position = "bottom", legend.box = "vertical")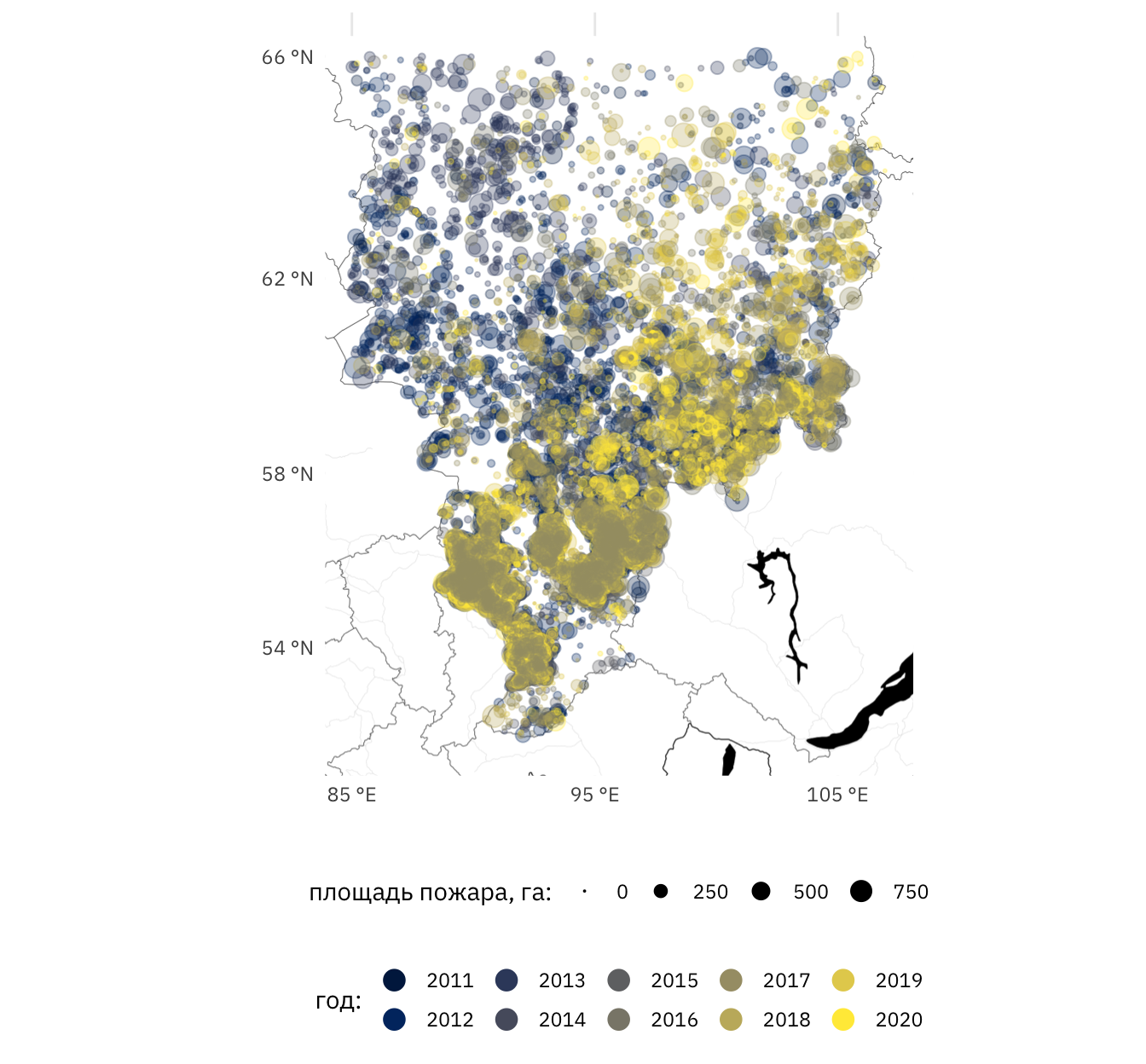
Рисунок 5: Пожары площадью менее 1 000 га в Красноярском крае в 2011-2020 годах. Размер точки пропорционален площади пожара, цвет соответствует году (темнее – старше)
Моделирование
Для моделирования методами машинного обучения мы будем использовать tidymodels – набор библиотек для моделирования основанных на принципах tidy data, которые объединяет единый подход и грамматика проектирования. Хорошим источником по введению в моделирование на языке R является готовящаяся к публикации книга Tidy Modeling with R. Далее рассмотрим основные этапы моделирования.
В качестве примера мы рассмотрим модель, которая предсказывает, насколько близко пожар может подойти к населенному району. Выберем 5-километровую зону в качестве критической и введем новую переменную, которая принимает два значения: далеко (если пожар произошел на расстоянии более 5 км от населенного пункта) и близко (если пожар находится в критической 5-километровой зоне).
wildfires <-
wildfires %>%
mutate(critical_distance =
case_when(Dist <= 5 ~ "близко",
TRUE ~ "далеко"))wildfires_model <- wildfires %>%
dplyr::select(critical_distance, Lon, Lat, Sdate, Place, Earea) %>%
mutate_if(is.character, factor) %>%
na.omit()
wildfires_model %>%
head(., 10) %>%
kbl() %>%
kable_paper("hover", full_width = F)| critical_distance | Lon | Lat | Sdate | Place | Earea |
|---|---|---|---|---|---|
| далеко | 83.47389 | 67.71389 | 2012-03-18 | Туруханское | 25 |
| далеко | 94.60806 | 55.17389 | 2012-03-29 | Саянское | 260 |
| далеко | 83.48389 | 67.71611 | 2012-03-30 | Туруханское | 274 |
| близко | 91.45306 | 53.76389 | 2012-03-31 | Боградское | 3 |
| далеко | 91.52389 | 53.84111 | 2012-04-01 | Минусинское | 97 |
| близко | 91.72389 | 53.17611 | 2012-04-04 | Саяно-Шушенское | 20 |
| близко | 91.89194 | 53.27195 | 2012-04-04 | Шушенский Бор НП | 28 |
| далеко | 83.48389 | 67.71611 | 2011-03-26 | Туруханское | 81 |
| близко | 92.76195 | 56.10389 | 2011-04-02 | Красноярское | 64 |
| близко | 92.83195 | 53.26805 | 2011-04-09 | Каратузское | 39 |
Таким образом, мы рассмотрим задачу классификации в зависимости от других предикторов. Согласно исходным данным, в 5-километровой зоне произошло 15 652 пожара, что составило чуть более 53% от общего числа пожаров за исследуемый период времени. Обратим внимание, что расстояние от фронта пожаров до населенных пунктов увеличивается с увеличением широты, поэтому широта должна быть одной из определяющих характеристик модели.
ewbrks <- seq(85,110,10)
nsbrks <- seq(round(min(wildfires$Lat)), round(max(wildfires$Lat)),5)
ewlbls <- unlist(lapply(ewbrks, function(x) ifelse(x > 0, paste(x, "°E"), ifelse(x < 0, paste(x, "°W"),x))))
nslbls <- unlist(lapply(nsbrks, function(x) ifelse(x < 0, paste(x, "°S"), ifelse(x > 0, paste(x, "°N"),x))))
wildfires %>%
ggplot(aes(Dist, Lat)) +
geom_point(alpha = 0.1) +
geom_smooth(se = F) +
scale_y_continuous(breaks = nsbrks, labels = nslbls, limits = range(wildfires$Lat)) +
silgelib::theme_plex() +
labs(x = "\nрасстояние до населенного пункта, км", y = "")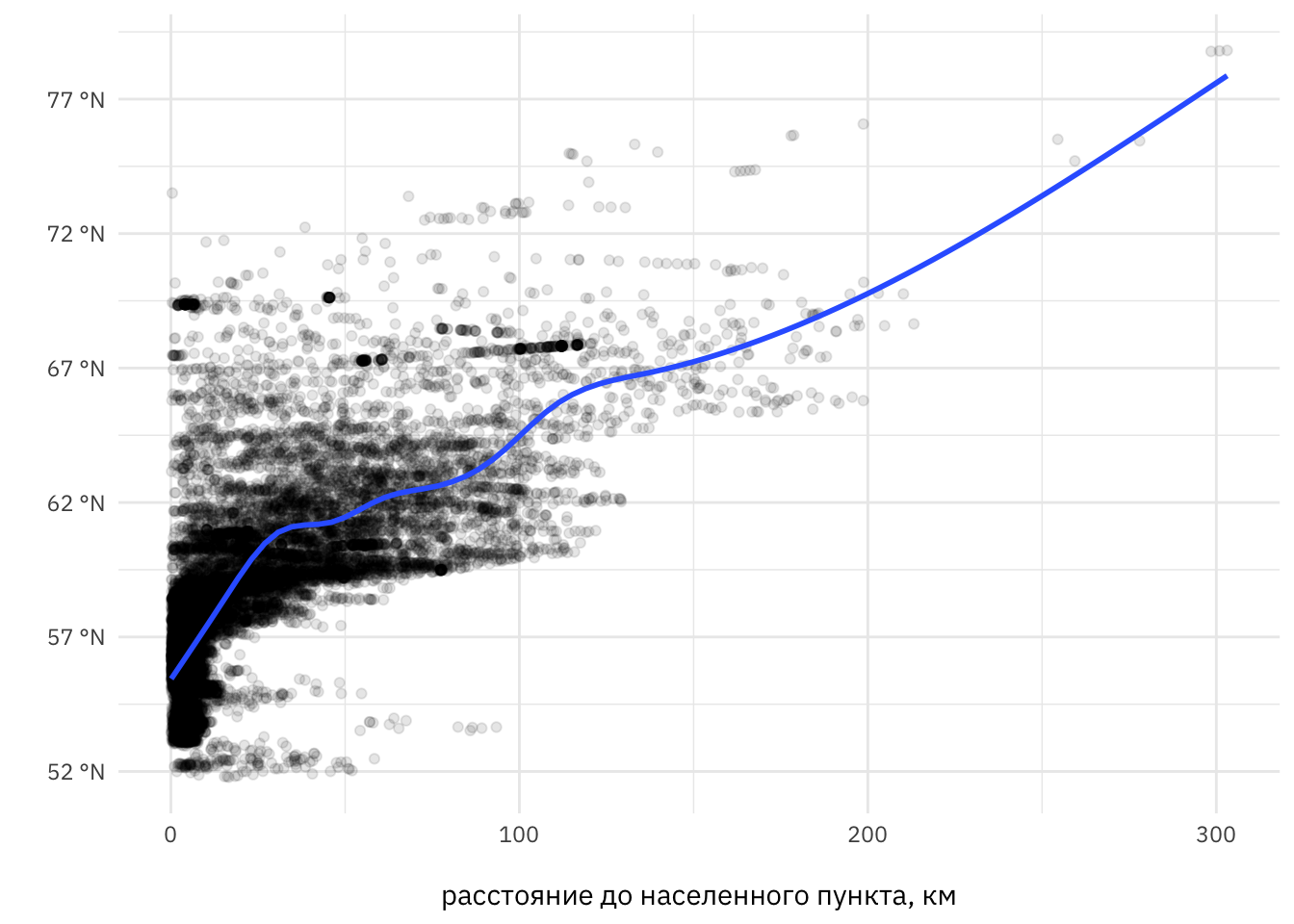
Рисунок 6: Расстояние от фронта пожаров до населенных пунктов Красноярского края за период 2011-2020 гг. Каждая точка представляет собой возникновение пожара, кривая синего цвета представляет собой сглаживание методом подгонки локальной полиномиальной регрессии
1. Разбиение выборки на два набора «обучающий» и «тестовый»
Разделим выборку на два набора: «обучающий», составляющий большую часть данных, используемый для разработки и оптимизации модели, и «тестовый» набор для определения эффективности модели. В нашем случае мы разделим всю выборку в пропорции 80% / 20%.
set.seed(123)
wildfires_split <- initial_split(wildfires_model, prop = 0.8)
wildfires_train <- training(wildfires_split)
wildfires_test <- testing(wildfires_split)Для ресамплинга геоданных в R также предусмотрена экспериментальная библиотека spatialsample, позволяющая формировать кластеры на основе широты и долготы на этапе разделения данных на обучающий и тестовый наборы, что улучшает результат моделирования. Мы разделим весь набор на 10 кластеров по географическому признаку.
wildfires_folds <- spatialsample::spatial_clustering_cv(wildfires_train,
coords = c("Lon", "Lat"),
v = 10)wildfires_folds## # 10-fold spatial cross-validation
## # A tibble: 10 × 2
## splits id
## <list> <chr>
## 1 <split [21564/1943]> Fold01
## 2 <split [16922/6585]> Fold02
## 3 <split [17698/5809]> Fold03
## 4 <split [22767/740]> Fold04
## 5 <split [21490/2017]> Fold05
## 6 <split [21859/1648]> Fold06
## 7 <split [22629/878]> Fold07
## 8 <split [22838/669]> Fold08
## 9 <split [20854/2653]> Fold09
## 10 <split [22942/565]> Fold102. Конструирование признаков (Feature Engineering) и декларация модели
Данный этап включает в себя действия, которые переформатируют значения предикторов чтобы упростить их эффективное использование в модели. Это включает в себя преобразование и кодирование данных для наилучшего представления их важных характеристик, например, уменьшение выборки для учета дисбаланса классов, и др. Некоторые модели используют геометрические метрики расстояний, и, следовательно, числовые предикторы должны быть центрированы и масштабированы так, чтобы все они были в одних и тех же единицах измерения. Подготовка данных и Feature Engineering является одним из самых сложных этапов моделирования. Книги Feature Engineering and Selection: A Practical Approach for Predictive Models и Feature Engineering Bookcamp являются хорошим введением в предметную область.
Для конструирования признаков используются команды начинающиеся с префикса step_() из библиотеки recipes. Командой recipe() устанавливается рабочий процесс модели (model workflow, называемый «рецептом»), здесь же указываются используемые данные и «формула», показывающая переменные модели и их зависимости (что является прогностическими параметрами – предикторами, а что искомым показателем).
wildfires_rec <- recipe(critical_distance ~ ., data = wildfires_model) %>%
step_date(Sdate) %>%
step_rm(Sdate) %>%
step_other(Place, threshold = 0.005, other = "Other") %>%
step_dummy(all_nominal(), -critical_distance) %>% # dummy codes categorical variables
step_nzv(all_predictors(), freq_cut = 0, unique_cut = 0) %>% # remove variables with zero variances
themis::step_downsample(critical_distance)## Registered S3 methods overwritten by 'themis':
## method from
## bake.step_downsample recipes
## bake.step_upsample recipes
## prep.step_downsample recipes
## prep.step_upsample recipes
## tidy.step_downsample recipes
## tidy.step_upsample recipes
## tunable.step_downsample recipes
## tunable.step_upsample recipeswildfires_rec## Recipe
##
## Inputs:
##
## role #variables
## outcome 1
## predictor 5
##
## Operations:
##
## Date features from Sdate
## Delete terms Sdate
## Collapsing factor levels for Place
## Dummy variables from all_nominal(), -critical_distance
## Sparse, unbalanced variable filter on all_predictors()
## Down-sampling based on critical_distanceПосле этого выбирается модель: tidymodels предоставляет огромный спектр практически всех известных моделей, включая модели Deep Learning. Модель декларируется с помощью команды set_engine(). Режим работы модели (классификация или регрессия) устанавливается командой set_mode(). В нашем случае это алгоритм «бэггинг» рассмотренный, например, в книге Классификация, регрессия и другие алгоритмы Data Mining с использованием R. Алгоритм «бэггинг» хорошо работает в классификационных задачах для географически распределенных данных что, например, отмечалось в статье Big data integration shows Australian bush-fire frequency is increasing significantly. Для более точной настройки можно использовать, например, алгоритм XGBoost.
bag_spec <- baguette::bag_tree(min_n = 10) %>%
set_engine("rpart", times = 20) %>% # 20 bootstrap resamples
set_mode("classification")
bag_spec## Bagged Decision Tree Model Specification (classification)
##
## Main Arguments:
## cost_complexity = 0
## min_n = 10
##
## Engine-Specific Arguments:
## times = 20
##
## Computational engine: rpart3. Настройка гиперпараметров модели и оценка результатов с помощью метрик
Соберем рабочий процесс модели.
wildfires_wf <- workflow() %>%
add_recipe(wildfires_rec) %>%
add_model(bag_spec)
wildfires_wf## ══ Workflow ════════════════════════════════════════════════════════════════════
## Preprocessor: Recipe
## Model: bag_tree()
##
## ── Preprocessor ────────────────────────────────────────────────────────────────
## 6 Recipe Steps
##
## • step_date()
## • step_rm()
## • step_other()
## • step_dummy()
## • step_nzv()
## • step_downsample()
##
## ── Model ───────────────────────────────────────────────────────────────────────
## Bagged Decision Tree Model Specification (classification)
##
## Main Arguments:
## cost_complexity = 0
## min_n = 10
##
## Engine-Specific Arguments:
## times = 20
##
## Computational engine: rpartЗдесь происходит создание настраиваемой спецификации модели, а также настройка (в том числе автоматическая!) гиперпараметров модели и объедение ее с «рецептом», полученном на предыдущем этапе в рабочем процессе. Удобство tidymodels заключается в том, что мы можем создать несколько моделей на одном и том же наборе данных и затем сравнить их (например, сравнить линейную модель с моделью, полученной с помощью Keras). Обучим модель используя параллельные вычисления.
doParallel::registerDoParallel()
wildfires_res <- fit_resamples(
wildfires_wf,
wildfires_folds,
control = control_resamples(save_pred = TRUE)
)Модель рассматривается на обучающей выборке и, по таблице метрик, проверяется, насколько хорошо выглядит результат моделирования (например, показатель метрики близок к 1).
collect_metrics(wildfires_res)## # A tibble: 2 × 6
## .metric .estimator mean n std_err .config
## <chr> <chr> <dbl> <int> <dbl> <fct>
## 1 accuracy binary 0.752 10 0.0809 Preprocessor1_Model1
## 2 roc_auc binary 0.651 10 0.0333 Preprocessor1_Model14. Распространение модели на все множество и проверка точности
При распространении модели на тестовую выборку метрики пересчитываются заново.
wildfires_fit <- last_fit(wildfires_wf, wildfires_split)
collect_metrics(wildfires_fit)## # A tibble: 2 × 4
## .metric .estimator .estimate .config
## <chr> <chr> <dbl> <fct>
## 1 accuracy binary 0.874 Preprocessor1_Model1
## 2 roc_auc binary 0.934 Preprocessor1_Model1Далее рассматривается матрица ошибок, показывающая точность модели.
collect_predictions(wildfires_fit) %>%
conf_mat(critical_distance, .pred_class) %>%
autoplot(., type = "heatmap")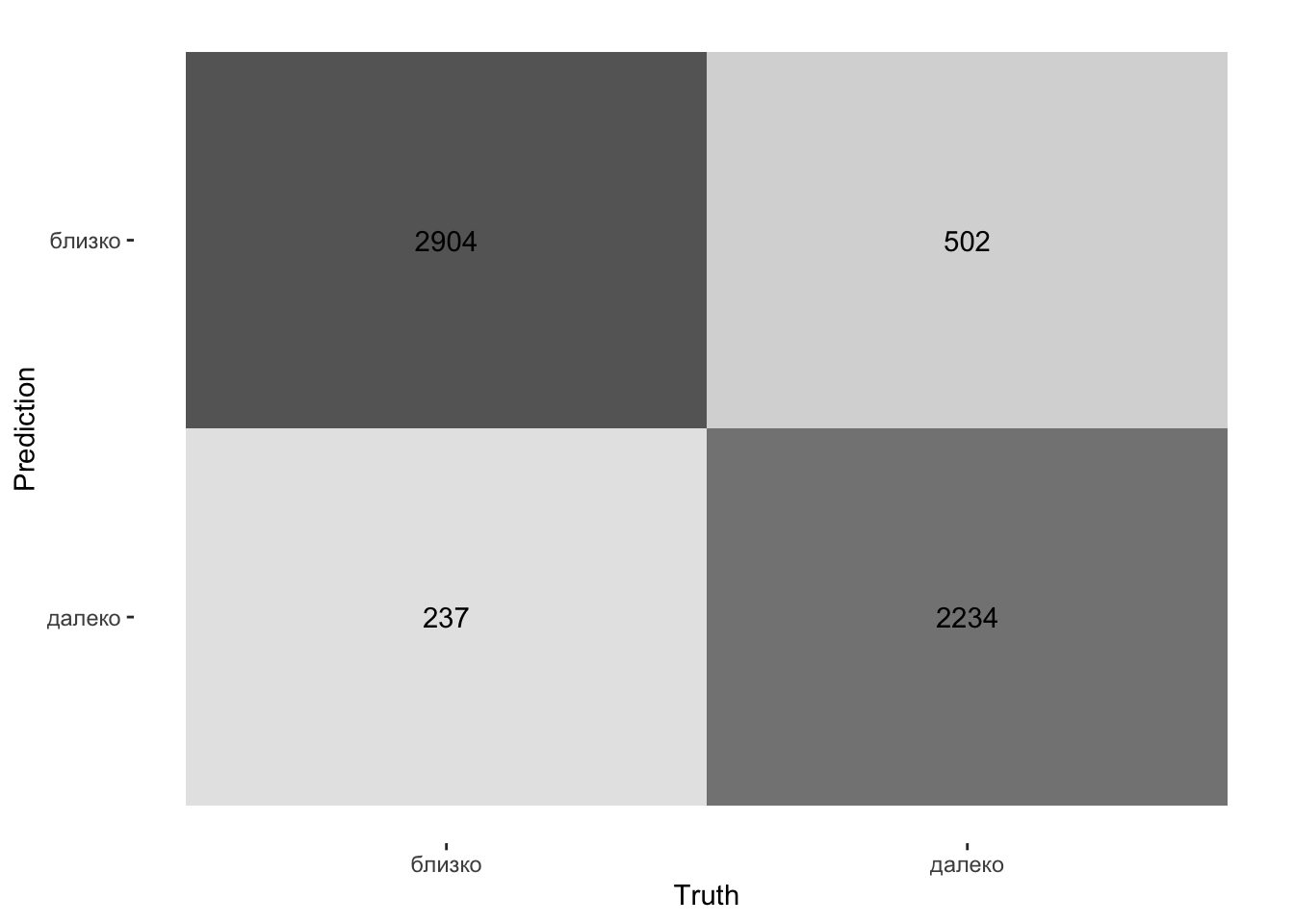
Рисунок 7: Матрица ошибок модели в виде тепловой карты
collect_predictions(wildfires_fit) %>%
conf_mat(critical_distance, .pred_class) %>%
autoplot(., type = "mosaic")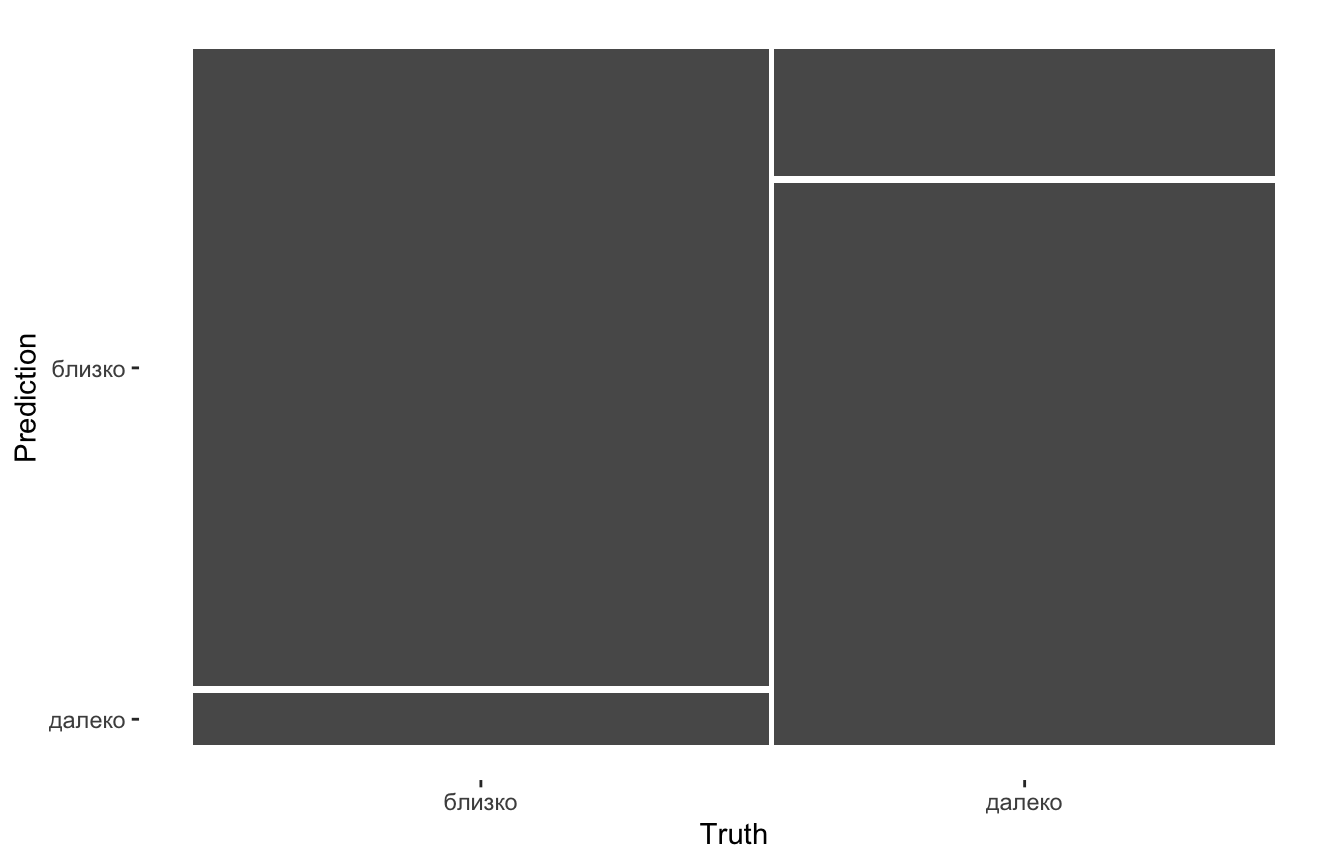
Рисунок 8: Матрица ошибок модели в виде мозаичной диаграммы
Также, точность моделирования можно оценивать с помощью ROC-кривой модели.
wildfires_fit %>%
collect_predictions() %>%
roc_curve(critical_distance, .pred_близко) %>%
ggplot(aes(x = 1 - specificity, y = sensitivity)) +
geom_line(size = 1.5, color = "midnightblue") +
geom_abline(
lty = 2,
alpha = 0.5,
color = "gray50",
size = 1.2
) +
coord_equal() +
silgelib::theme_plex()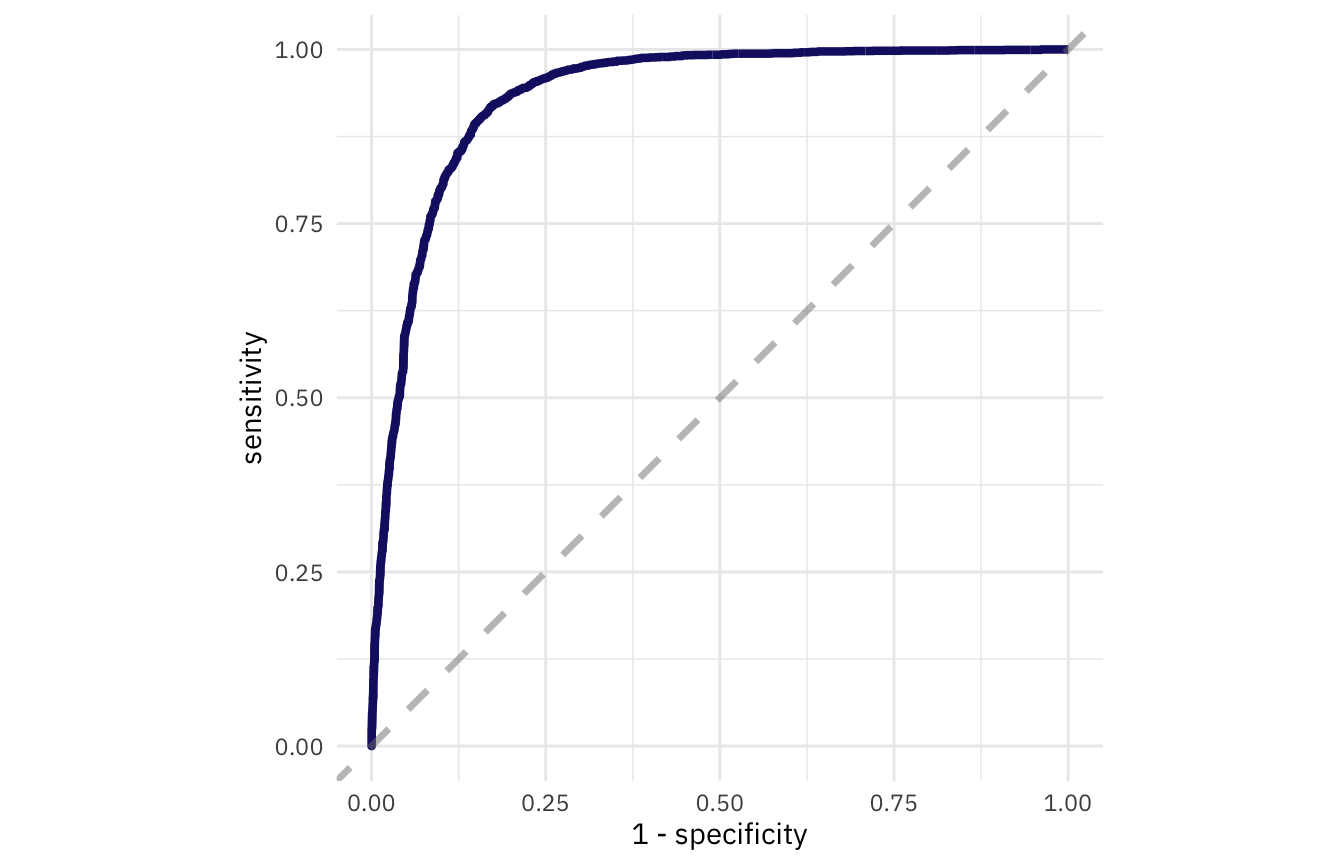
Рисунок 9: ROC-кривая модели
Окончательно, если модель показывает удовлетворительные результаты, рассматривают значимость признаков модели. Как и ожидалось, наибольшую значимость имеют географические координаты.
wildfires_imp <- wildfires_fit$.workflow[[1]] %>%
extract_fit_parsnip()wildfires_imp$fit$imp %>%
slice_max(value, n = 10) %>%
ggplot(aes(value, fct_reorder(term, value))) +
geom_col(alpha = 0.8, fill = "midnightblue") +
labs(x = "", y = "") +
scale_x_continuous(labels = function(x) format(x, big.mark = " ", scientific = FALSE)) +
silgelib::theme_plex()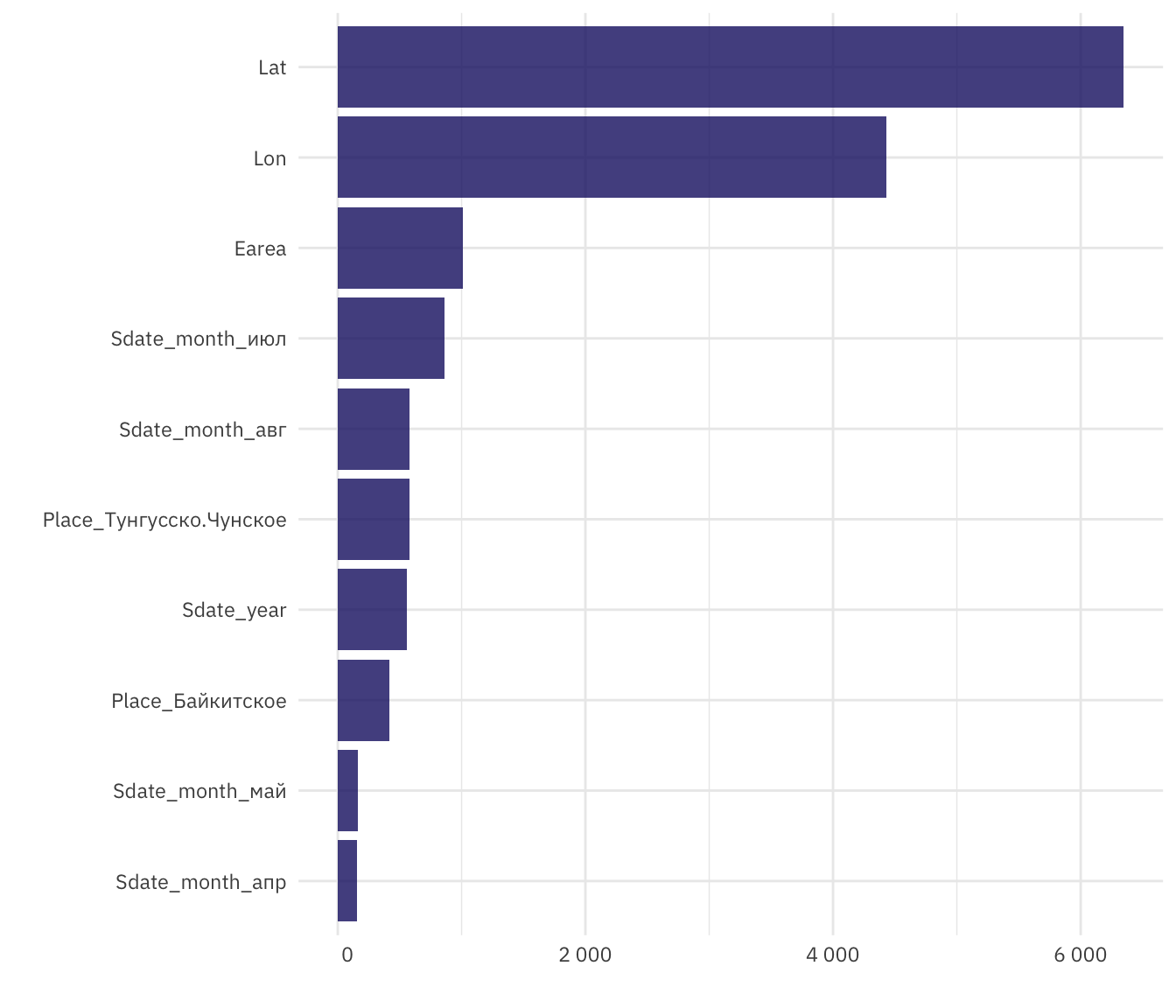
Рисунок 10: Значимость предикторов
С помощью гексагональной карты покажем процент правильно классифицированных пожаров. Для наглядности на карту нанесены населенные пункты.
wildfires_pred <-
wildfires_res %>%
collect_predictions() %>%
mutate(correct = (critical_distance == .pred_class) | ((critical_distance == "далеко") & (.pred_class == "близко")) ) %>%
left_join(wildfires_train %>%
mutate(.row = row_number()))## Joining, by = c(".row", "critical_distance")library(ggmap)
ggmap(quater_map) +
coord_cartesian() +
stat_summary_hex(
data = wildfires_pred,
aes(Lon, Lat, z = as.integer(correct)),
fun = "mean",
alpha = 0.8, bins = 40
) +
viridis::scale_fill_viridis(labels = scales::percent, direction = -1) +
scale_x_continuous(breaks = ewbrks, labels = ewlbls, limits = c(87, 103)) +
scale_y_continuous(breaks = nsbrks, labels = nslbls, limits = c(52, 59)) +
guides(fill = guide_legend(reverse = TRUE, override.aes = list(alpha = 0.8))) +
silgelib::theme_plex() +
labs(x = NULL, y = NULL,
fill = "Процент правильно\nклассифицированных\nпожаров\n", size = "население, тыс. чел.") +
geom_point(data = cities_KRSK_krai,
aes(longitude_dd, latitude_dd, size = (population)/1000), alpha = 0.7, color = "black") +
scale_size(range = c(0, 10)) 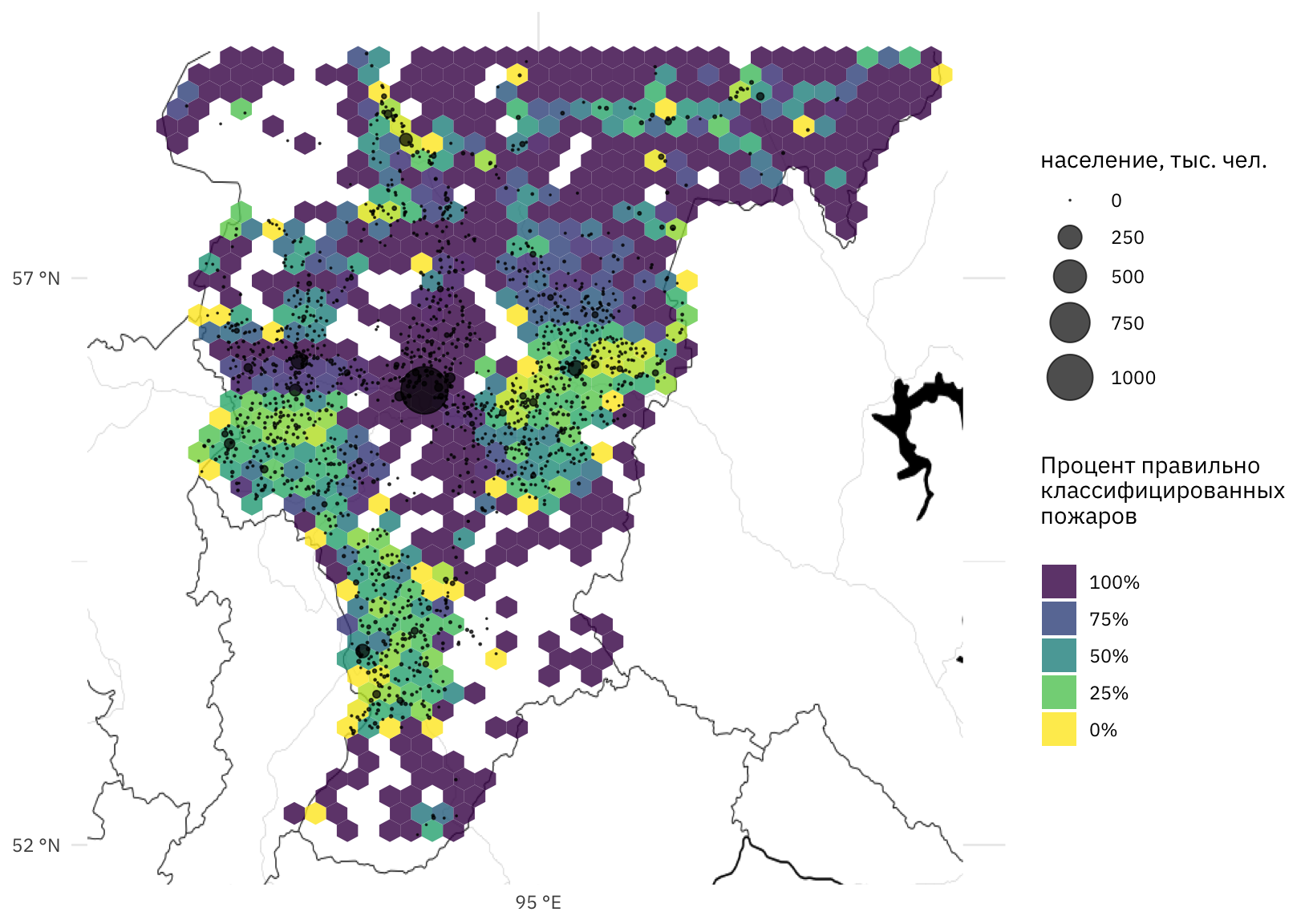
Рисунок 11: Гексагональная карта, показывающая процент правильно классифицированных пожаров по принадлежности 5-километровой зоне (от светлого – 0% к темному – 100%), на карту также нанесены населенные пункты
Точки на карте, соответствующие населенным пунктам, в основном лежат в диапазоне 25%–75% правильной классификации, территории около крупных населенных пунктов классифицируются хорошо. Мы видим, что несмотря на достаточно хорошую общую точность модели, для географически распределенных данных является актуальным улучшение локальной точности при моделировании на территориях с большими площадями, поскольку для удаленных участков (площадь которых может быть достаточно большой) модель может показывать хорошую точность, но не вблизи населенных пунктов, т.е. там, где это необходимо.
Заключение
В статье был рассмотрен базовый анализ географически распределенных данных на примере ситуаций с лесными пожарами в Красноярском крае за период 2011-2020 года. Мы показали некоторые основные приемы работы с географическими данными, но не рассматривали, например, геостатистический анализ на основе моделирования вариограм, кригинга и т.д. Часть материала, который рассмотрен здесь, будет опубликована в рамках HETS 2021: Международный научно-практический форум по проблемам устойчивого развития в цифровом мире: Человек. Экономика. Технологии. Социум в сборнике статей издательства Springer.
Рассмотренные в статье инструменты и модели имеют как теоретическое, так и практическое значение, например, для определения рисков приближения нелокализованных пожаров к критической 5-километровой зоне на основе оперативных данных вокруг населенного пункта или объекта инфраструктуры. Подходы, используемые здесь, могут быть аналогичным образом распространены на другие регионы Российской Федерации. Рассмотренная здесь простейшая модель машинного обучения в настоящий момент не учитывает множество сопутствующих показателей: метеоданные, Normalized Difference Vegetation Index (NDVI), и т.д. Более глубокий анализ аналогичного характера рассматривался в хакатоне NoFireWithAI, задачей которого являлось прогнозирование пожаров в Российской Федерации используя информацию на определенном участке внутри элементов сетки-разбиения всей территории РФ. Использование моделей машинного обучения позволило внедрить МЧС России мобильное приложение «Термические точки» для автоматического информирования о риске возгорания для ускоренного реагирования на природные пожары. Приложение получило высокую оценку специалистов и стало победителем AI Russia Awards в номинации «Социально значимый проект».
О современных глобальных тенденциях, текущих и прогнозируемых изменениях активности лесных пожаров можно прочитать в статье ниже.
#wildfires are currently raging across the globe.
— Nature Reviews Earth & Environment 🌍 (@NatRevEarthEnv) July 20, 2021
Learn more about current and projected changes in wildfire activity in this Review by Bowman et al.https://t.co/P2sWDwWJ7r (free-to-read: https://t.co/Vu9z2upnyL) pic.twitter.com/wpXvQ7n9sW
Автор выражает глубокую благодарность Валерию Васильевичу Ничепорчуку, старшему научному сотруднику Института вычислительного моделирования СО РАН, за предоставленные данные, поддержку и полезные обсуждения.
Евгений Матеров
Зав. кафедрой физики, математики и информационных технологий
Область моих научных интересов включает в себя Data Science, машинное обучение, язык программирования R.