Анализ пожаров Красноярского края за 2010-2020 года (1 часть)
пример базового анализа данных по пожарам с использованием языка программирования R; данным сопоставляется временной ряд, исследуются: пропуски в заполнении исходных данных, периодические компоненты, тренд и аномалии временного ряда.
Исходные данные
Рассмотрим данные по пожарам в Красноярском крае1. Основными переменными являются: дата пожара (переменная f5), район края (переменная f2) и вид населенного пункта (переменная f6). Каждая строка данных соответствует одному событию – пожару.
pozh_df## # A tibble: 196,031 x 3
## f2 f5 f6
## <fct> <date> <fct>
## 1 Абанский район 2010-01-01 Населенный пункт городского типа
## 2 Абанский район 2010-01-03 Сельский населенный пункт
## 3 Абанский район 2010-01-03 Сельский населенный пункт
## 4 Канск 2010-01-12 Город
## 5 Абанский район 2010-01-05 Населенный пункт городского типа
## 6 Абанский район 2010-01-06 Сельский населенный пункт
## 7 Абанский район 2010-01-10 Вне территории населенного пункта
## 8 Шарыповский район 2010-01-05 Сельский населенный пункт
## 9 Абанский район 2010-01-11 Населенный пункт городского типа
## 10 Абанский район 2010-01-11 Населенный пункт городского типа
## # … with 196,021 more rowsДиапазон дат наших данных охватывает период с 2010 по 2020 года.
range(pozh_df$f5)## [1] "2010-01-01" "2020-12-02"Используя функцию count(), выделим районы с наибольшим количеством пожаров.
count(pozh_df, f2, sort = T)## # A tibble: 66 x 2
## f2 n
## <fct> <int>
## 1 Красноярск (Советский район) 13906
## 2 Емельяновский район 12581
## 3 Ачинск 9998
## 4 Красноярск (Октябрьский район) 9814
## 5 Березовский район 9639
## 6 Красноярск (Ленинский район) 8799
## 7 Канск 8662
## 8 Красноярск (Свердловский район) 8288
## 9 Норильск 6951
## 10 Рыбинский район 6030
## # … with 56 more rowsНаибольшее количество пожаров наблюдалось в городской черте.
count(pozh_df, f6, sort = T)## # A tibble: 9 x 2
## f6 n
## <fct> <int>
## 1 Город 119739
## 2 Сельский населенный пункт 51259
## 3 Вне территории населенного пункта 13926
## 4 Населенный пункт городского типа 10918
## 5 Станция 94
## 6 Жилой поселок при станции 46
## 7 Вахтовый поселок 19
## 8 Разъезд, перегон 18
## 9 вид населенного пункта не указан 12Составим таблицу количества пожаров сразу по двум категориям: по районам края и видам населенных пунктов.
count(pozh_df, f2, f6, sort = T)## # A tibble: 255 x 3
## f2 f6 n
## <fct> <fct> <int>
## 1 Красноярск (Советский район) Город 13906
## 2 Красноярск (Октябрьский район) Город 9811
## 3 Ачинск Город 9199
## 4 Красноярск (Ленинский район) Город 8799
## 5 Канск Город 8637
## 6 Красноярск (Свердловский район) Город 8288
## 7 Емельяновский район Сельский населенный пункт 7769
## 8 Норильск Город 6942
## 9 Красноярск (Кировский район) Город 6024
## 10 Лесосибирск Город 5144
## # … with 245 more rowsОтобразим полученную табличную информацию графически, выделив только основные категории и упорядочив отдельные графики по убыванию. Оставим только категории с наибольшим количеством элементов, отнеся остальные категории в другие и организовав графики в виде матриц (используя так называемое панелирование).
library(tidytext)
pozh_df %>%
# оставляем 4 значимых вида населенных пунктов
mutate(f6 = fct_lump(f6, 4, other_level = "другие населенные пункты")) %>%
# оставляем максимум 25 значимых районов
mutate(f2 = fct_lump(f2, 10, other_level = "другие районы")) %>%
count(f2, f6) %>%
# упорядочиваем внутри каждой категории
mutate(f2 = reorder_within(f2, n, f6)) %>%
mutate(f6 = fct_reorder(f6, n, sum) %>% fct_rev()) %>%
# график
ggplot(aes(x = f2, y = n, fill = f6)) +
geom_col(show.legend = FALSE) +
# панели
facet_wrap(~f6, scales = "free", ncol = 2) +
coord_flip() +
scale_x_reordered() +
# разряды для тысяч
scale_y_continuous(expand = c(0,0), labels = function(x) format(x, big.mark = " ", scientific = FALSE)) +
labs(x = "", y = "")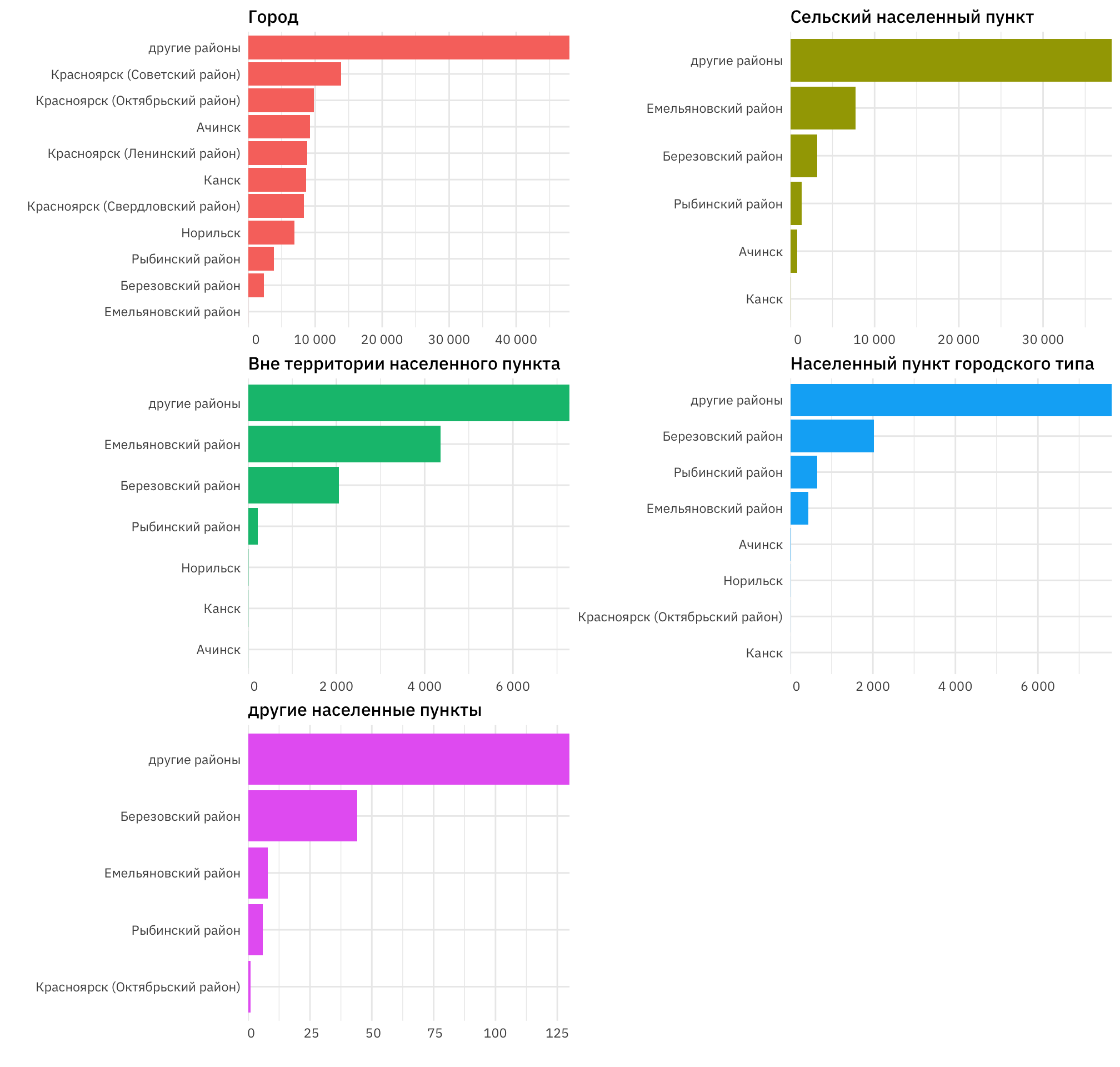
Рисунок 1: Количество пожаров по районам и видам населенных пунктов Красноярского края
Визуализируем количество пожаров, наблюдаемых в сутки, по видам населенных пунктов в виде “боксплотов” или диаграмм размаха. Боксплоты упорядочим по значению медиан.
pozh_df %>%
count(f6, f5) %>%
ggplot(., aes(x = f6 %>% fct_reorder(., n, median), y = n, fill = f6)) +
geom_boxplot(alpha = 0.8) + coord_flip() +
labs(y = "\nколичество пожаров в сутки, ед.", x = "") +
theme(legend.position = "none")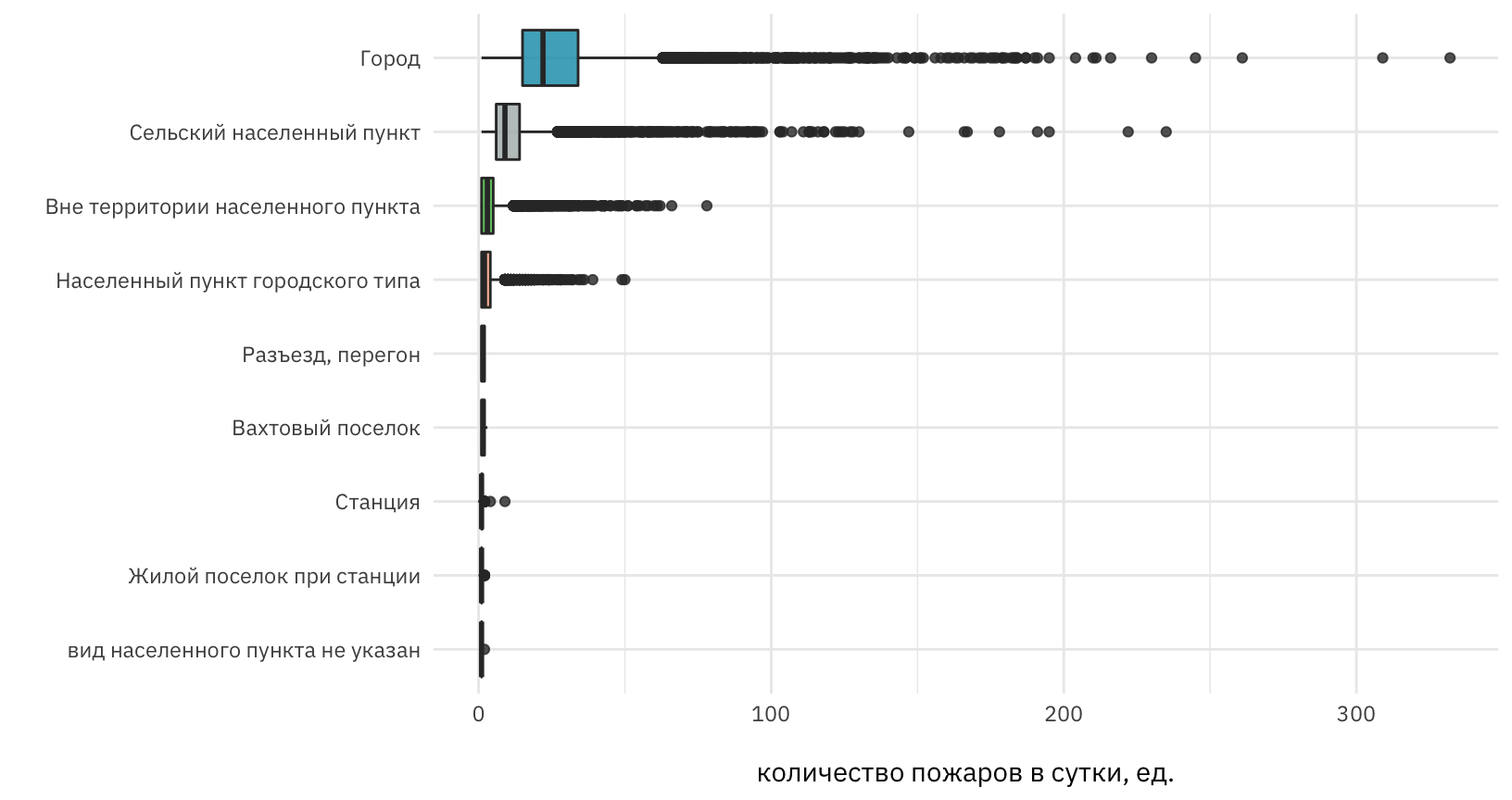
Рисунок 2: Количество количество пожаров в сутки по видам населенных пунктов
Напомним, что отдельные выбросы на данной диаграмме отображаются точками. Например, для городской категории более 50 пожаров в сутки можно считать “выбросом”, для сельских населенных пунктов – более 25 пожаров.
Временной ряд соответствующий количеству пожаров
Визуализация временного ряда по различным категориям
Поставим в соответствие ежедневному количеству пожаров в Красноярском крае временной ряд.
pozh_df %>%
group_by(f5) %>%
summarise(count = n()) %>%
ungroup() %>%
ggplot(., aes(x = f5, y = count)) + geom_line() +
labs(x = "", y = "") +
scale_x_date(date_breaks = "12 months",
date_labels = "%Y")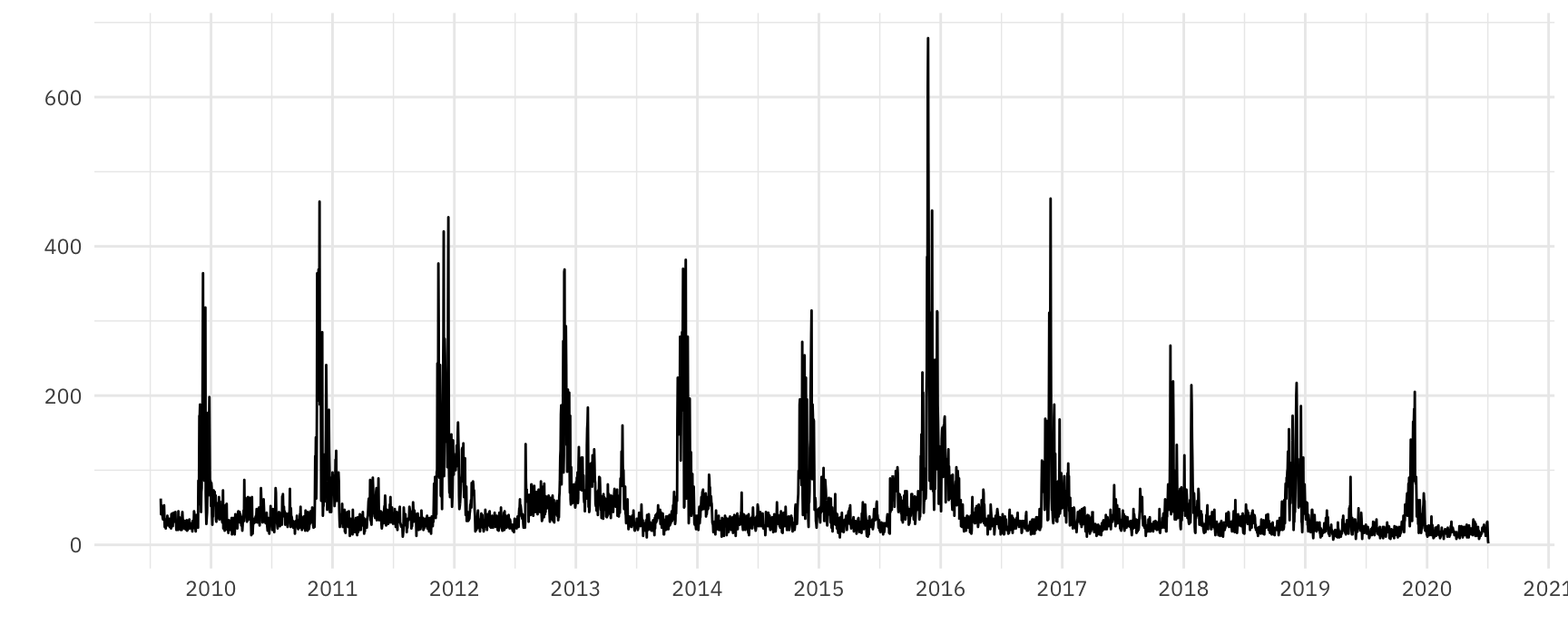
Рисунок 3: Общий вид временного ряда, соответствующего количеству пожаров в Красноярском крае с 2010 по 2020 год
На графике хорошо видны периодические всплески количества пожаров (как мы покажем далее, с апреля по июль).
Визуализируем временной ряд по видам населенных пунктов.
pozh_df %>%
mutate(f6 = fct_lump(f6, 3, other_level = "другие населенные пункты")) %>%
group_by(f6, f5) %>%
summarise(count = n()) %>%
ungroup() %>%
group_by(f6) %>%
mutate(total = sum(count)) %>%
ungroup() %>%
mutate(f6 = fct_reorder(f6, -total)) %>%
ggplot(., aes(x = f5, y = count)) + geom_line() +
labs(x = "", y = "") +
facet_wrap(~ f6, ncol = 2)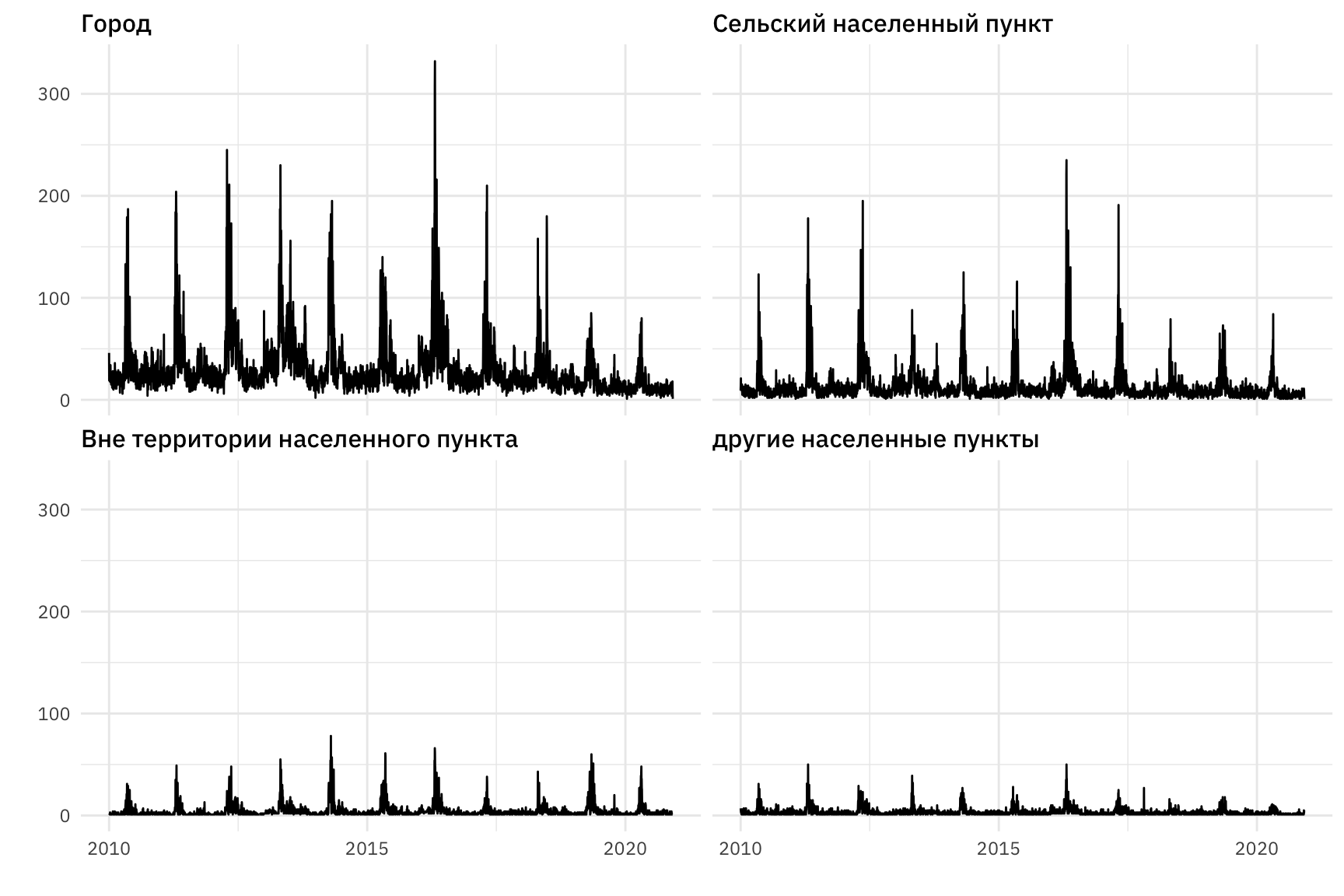
Рисунок 4: Вид временного ряда, соответствующего количеству пожаров в Красноярском крае с 2010 по 2020 год по видам населенных пунктов
Рассмотрим несколько районов с наибольшим количеством пожаров.
pozh_df %>%
mutate(f2 = fct_lump(f2, 11, other_level = "другие районы")) %>%
group_by(f2, f5) %>%
summarise(count = n()) %>%
ungroup() %>%
group_by(f2) %>%
mutate(total = sum(count)) %>%
ungroup() %>%
mutate(f2 = fct_reorder(f2, -total)) %>%
ggplot(., aes(x = f5, y = count)) + geom_line(alpha = 0.8) + geom_smooth(se = F) +
labs(x = "", y = "") +
facet_wrap(~ f2, scales = "free", ncol = 4)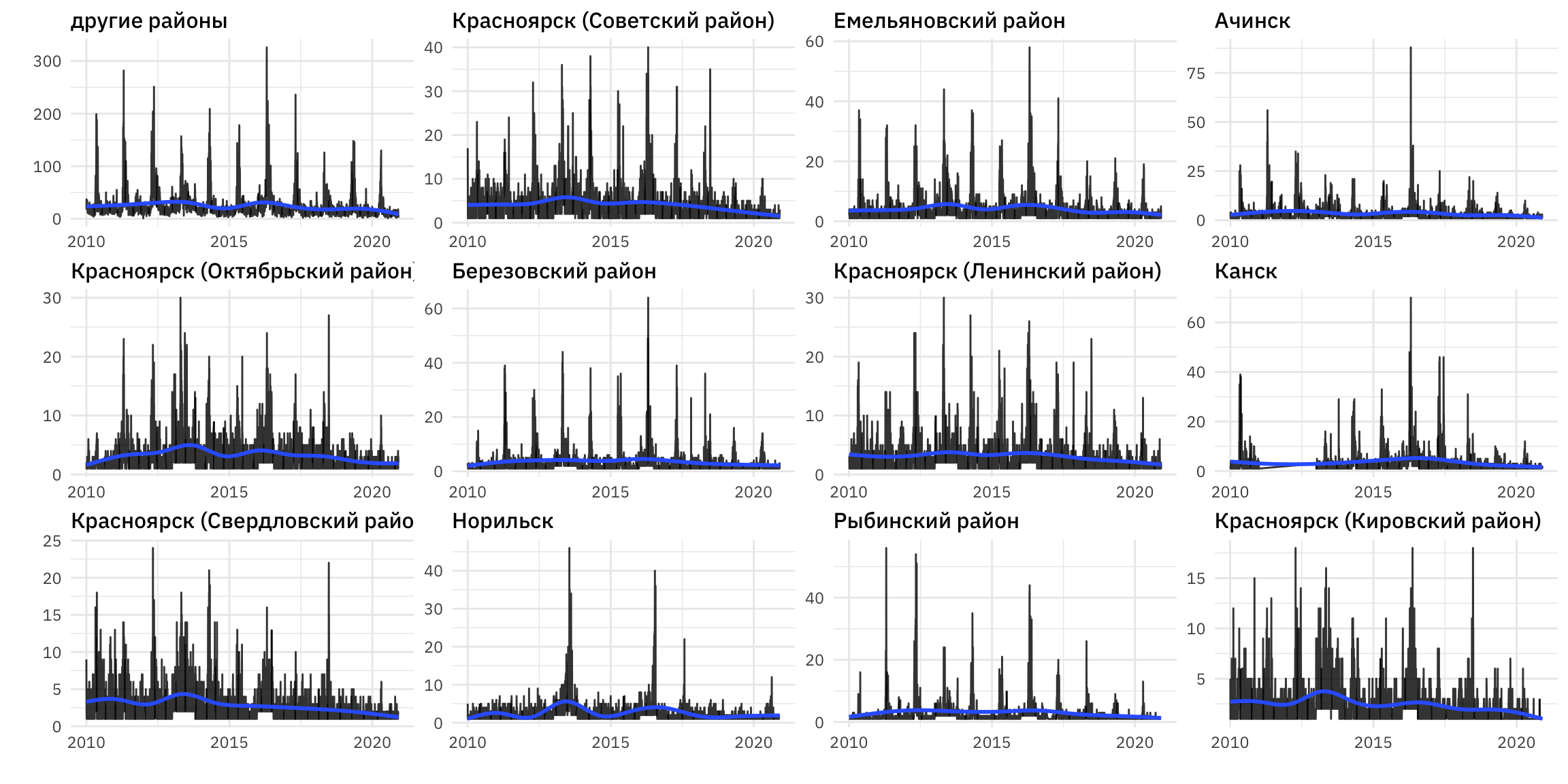
Рисунок 5: Вид временного ряда, соответствующего количеству пожаров в Красноярском крае с 2010 по 2020 год по районам края
Отметим существование пропусков в данных по некоторым районам края, например, по Сосновоборску, Лесосибирску, и т.д. Подробнее пропуски будут рассмотрены ниже.
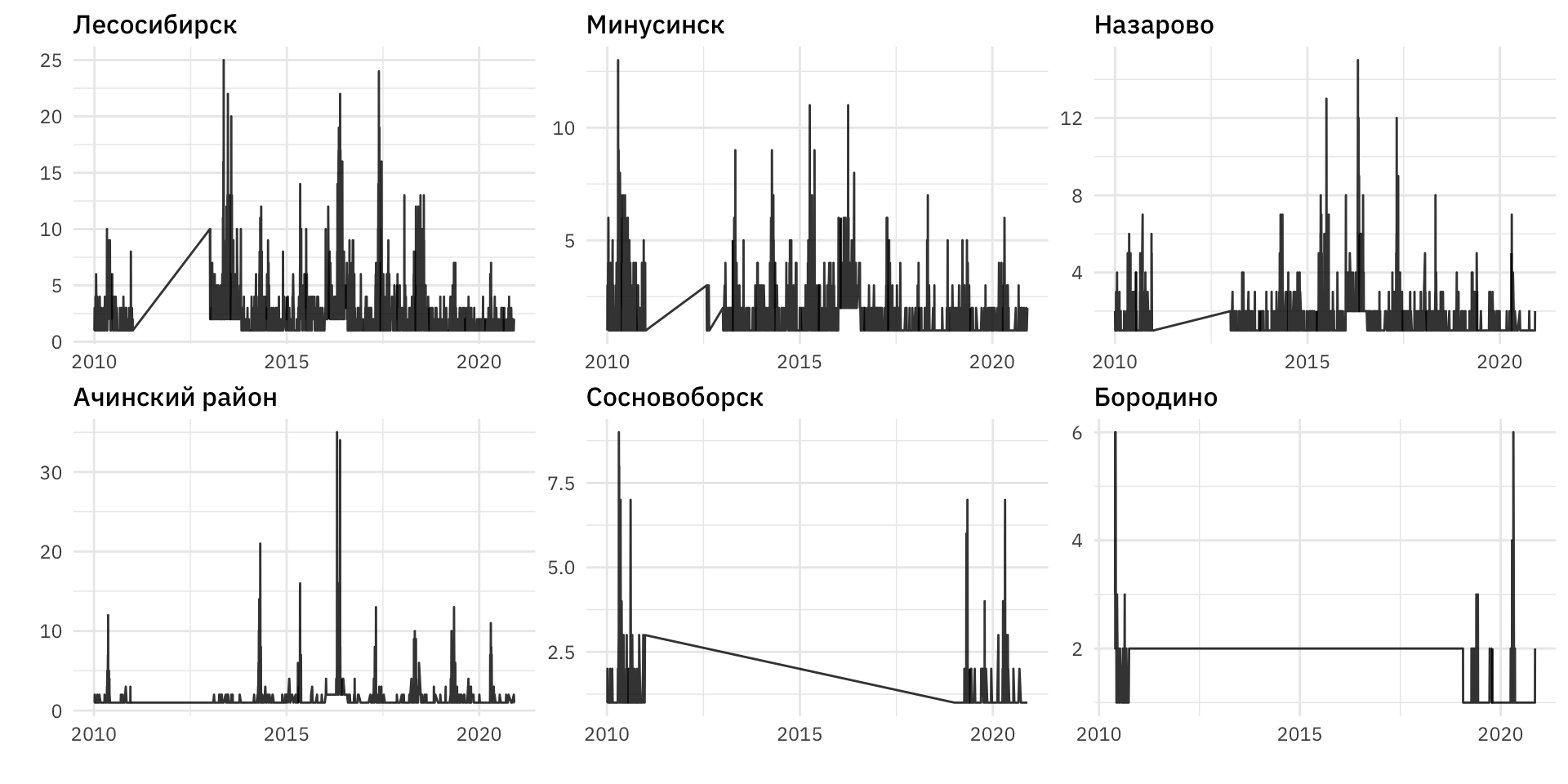
Рисунок 6: Пропуски в данных по некоторым районам Красноярского края
Временной ряд
Для работы с данными как с временным рядом будем использовать формат tsibble, присвоив в качестве ключа районы края.
require(tsibble)
# key = районы края
pozh_ts <- pozh_df %>%
group_by(f2, f5) %>%
summarise(y = n()) %>%
ungroup() %>%
as_tsibble(., key = f2, index = f5)Отметим, что пропущенные данные имеются во всех районах края, пропущено (либо в этот день не наблюдалось пожаров) более 170 000 значений!
# пропущенные значения есть во всех районах!
has_gaps(pozh_ts) ## # A tibble: 66 x 2
## f2 .gaps
## <fct> <lgl>
## 1 Абанский район TRUE
## 2 Ачинск TRUE
## 3 Ачинский район TRUE
## 4 Байкит TRUE
## 5 Балахтинский район TRUE
## 6 Березовский район TRUE
## 7 Бирилюсский район TRUE
## 8 Боготольский район TRUE
## 9 Богучанский район TRUE
## 10 Большемуртинский район TRUE
## # … with 56 more rows# пропущено более 170 000 значений
scan_gaps(pozh_ts)## # A tsibble: 179,619 x 2 [1D]
## # Key: f2 [66]
## f2 f5
## <fct> <date>
## 1 Абанский район 2010-01-02
## 2 Абанский район 2010-01-04
## 3 Абанский район 2010-01-07
## 4 Абанский район 2010-01-08
## 5 Абанский район 2010-01-09
## 6 Абанский район 2010-01-12
## 7 Абанский район 2010-01-13
## 8 Абанский район 2010-01-14
## 9 Абанский район 2010-01-16
## 10 Абанский район 2010-01-17
## # … with 179,609 more rowsСамые большие пропуски данных по длительности наблюдались в Бородино и Сосновоборске.
count_gaps(pozh_ts) %>% arrange(desc(.n))## # A tibble: 37,288 x 4
## f2 .from .to .n
## <fct> <date> <date> <int>
## 1 Бородино 2010-10-14 2019-01-22 3023
## 2 Сосновоборск 2010-12-28 2018-12-31 2926
## 3 Ачинский район 2010-12-30 2013-01-02 735
## 4 Шарыповский район 2010-12-29 2012-12-31 734
## 5 Канск 2011-01-01 2012-12-31 731
## 6 Лесосибирск 2011-01-01 2012-12-31 731
## 7 Назарово 2011-01-01 2012-12-31 731
## 8 Диксон 2012-09-13 2014-07-05 661
## 9 Диксон 2014-07-07 2016-04-25 659
## 10 Минусинск 2011-01-01 2012-07-30 577
## # … with 37,278 more rowsВизуализируем все возможные пропуски в районах по годам в виде тепловой карты. Можно допустить, что в некоторых районах края (например, в отдаленном Эвенкийском районе) было мало пожаров за исследуемый период, однако, в некоторых районах пропуски затрагивают целые года. Меньше всего пропусков наблюдалось в районах города Красноярска.
mosaic_gaps <-
tibble(scan_gaps(pozh_ts)$f2, scan_gaps(pozh_ts)$f5 %>% lubridate::year()) %>%
purrr::set_names("region", "year") %>% count(., region, year)
mosaic_gaps$year %<>% as.factor()
mosaic_gaps %>%
ggplot(., aes(x = region %>% fct_rev(), y = year, fill = n)) + coord_flip() + geom_tile() +
viridis::scale_fill_viridis(direction = -1, option = "cividis") +
labs(x = "", y = "", fill = "количество пропусков\n(темнее - больше)") 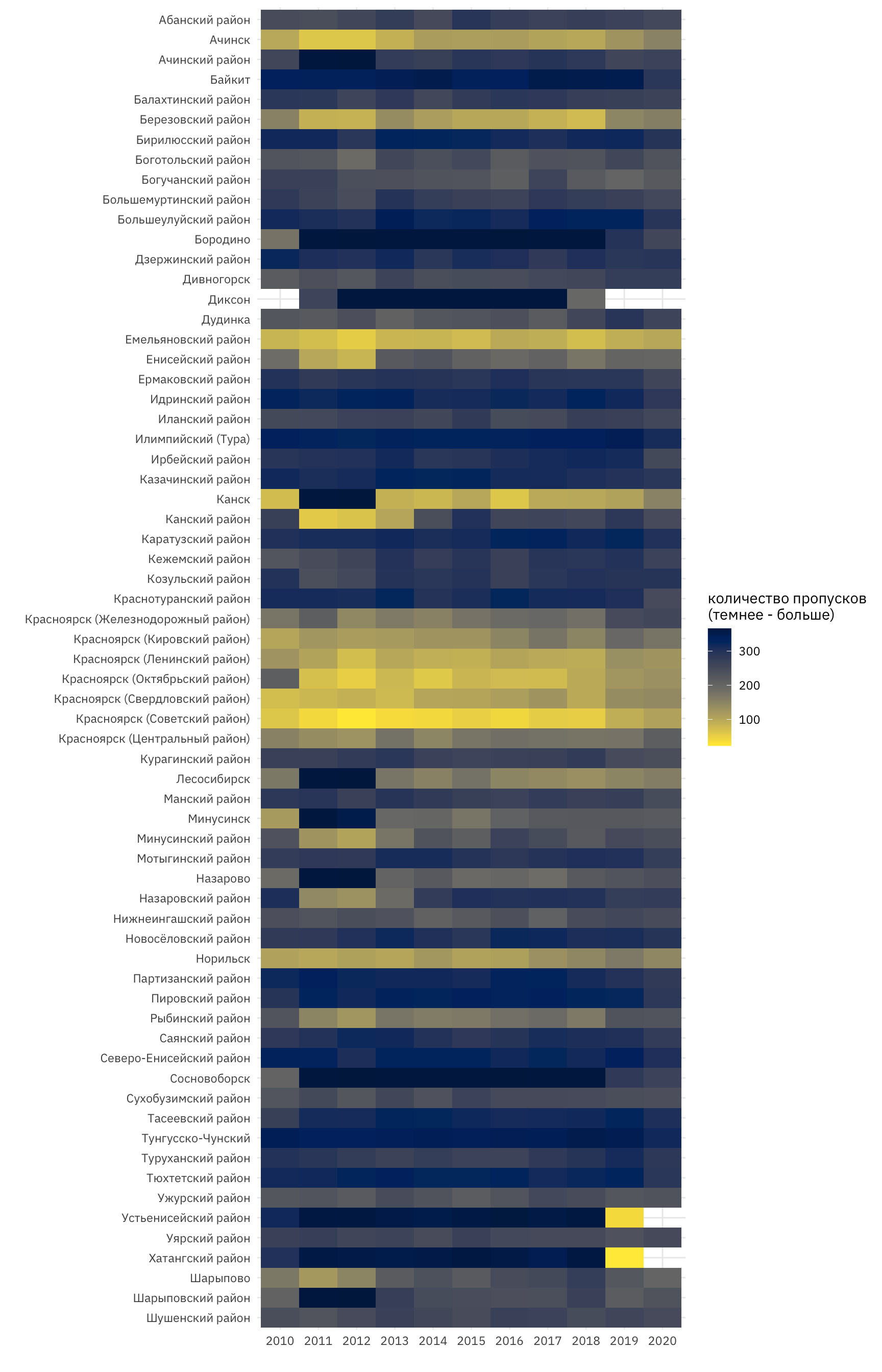
Рисунок 7: Пропуски в данных по пожарам по районам Красноярского края
Рассмотрим стандартное STL-разложение ряда на аддитивные компоненты:
- тренд (регулируемый параметром
window, чем он больше, тем тренд более плавный); - сезонная (здесь – годовая) повторяющаяся компонента;
- остаток (по сути – “белый шум”).
library(ggfortify)
library(feasts)
library(tsibble)
pozh_df %>%
group_by(f5) %>%
summarise(y = n()) %>%
ungroup() %>%
as_tsibble(., index = f5) %>%
model(STL(y ~ trend(window = 300) + season(period = "year"))) %>%
components() %>%
autoplot() +
labs(x = "") +
scale_x_date(date_breaks = "12 months",
date_labels = "%Y") + theme_minimal()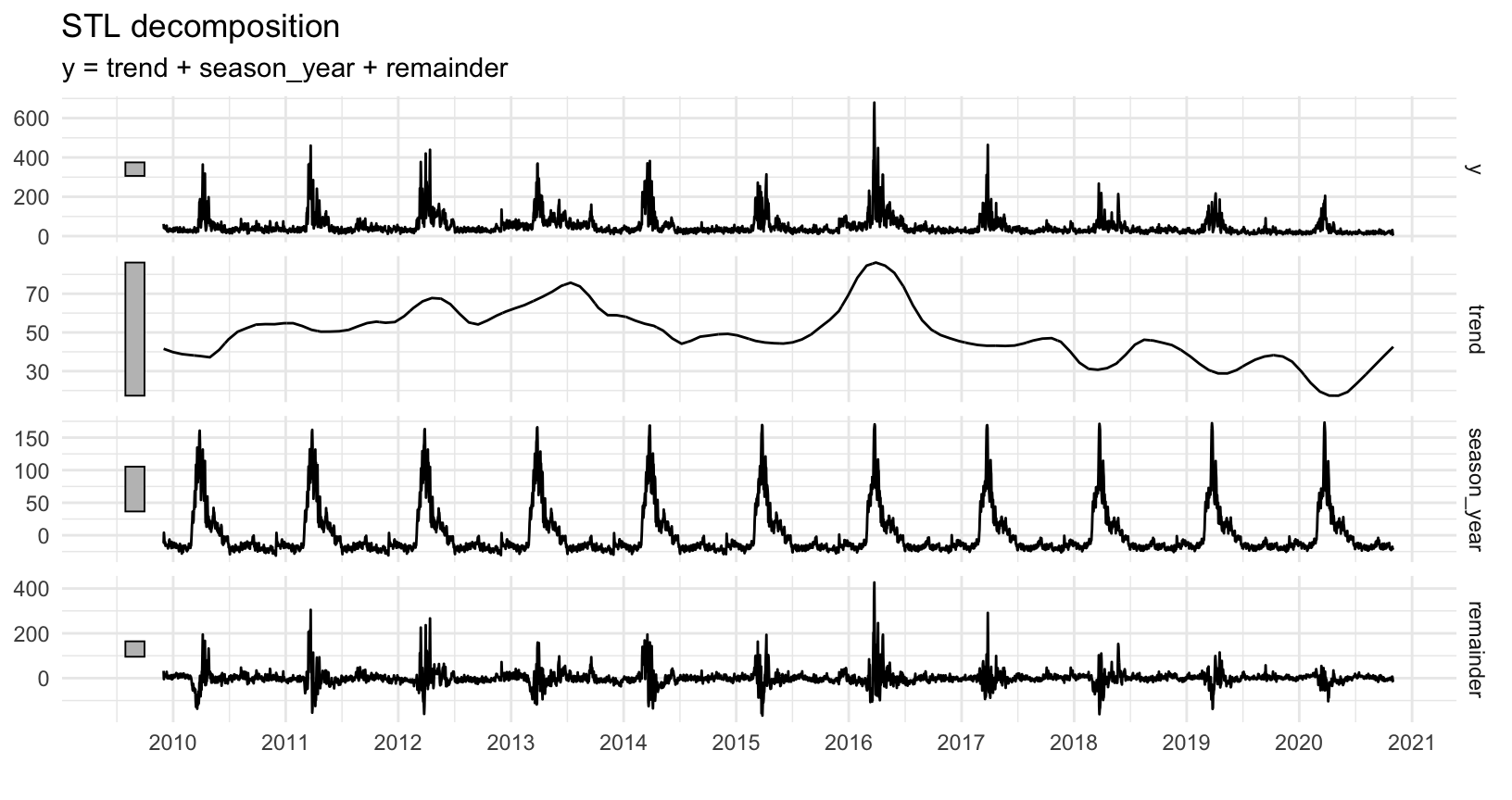
Рисунок 8: STL-разложение временного ряда
Разложение компоненты ценно тем, что позволяет выделить ежегодно повторяющееся количество пожаров (season_yearly) и подробно исследовать тренд (trend).
Работа в библиотеке Prophet
Для дальнейшего исследования временных рядов подключим библиотеку Prophet.
library(prophet)
pozh_prophet <- pozh_df %>%
select(f5) %>%
count(., f5, name = "y") %>%
rename("ds" = f5)
m <- prophet(pozh_prophet)Рассмотрим прогноз на 1 год вперед по совокупным данным.
future <- make_future_dataframe(m, periods = 365)
forecast <- predict(m, future)
tail(forecast[c('ds', 'yhat', 'yhat_lower', 'yhat_upper')])## ds yhat yhat_lower yhat_upper
## 4349 2021-11-27 6.9027206 -40.65369 53.42302
## 4350 2021-11-28 6.4249115 -39.44063 58.42009
## 4351 2021-11-29 -0.3397986 -46.32481 46.61351
## 4352 2021-11-30 -4.7742883 -54.98862 42.91211
## 4353 2021-12-01 -4.3767039 -49.71535 43.98105
## 4354 2021-12-02 -3.1958043 -50.89533 44.57331Визуализируем прогноз.
plot(m, forecast)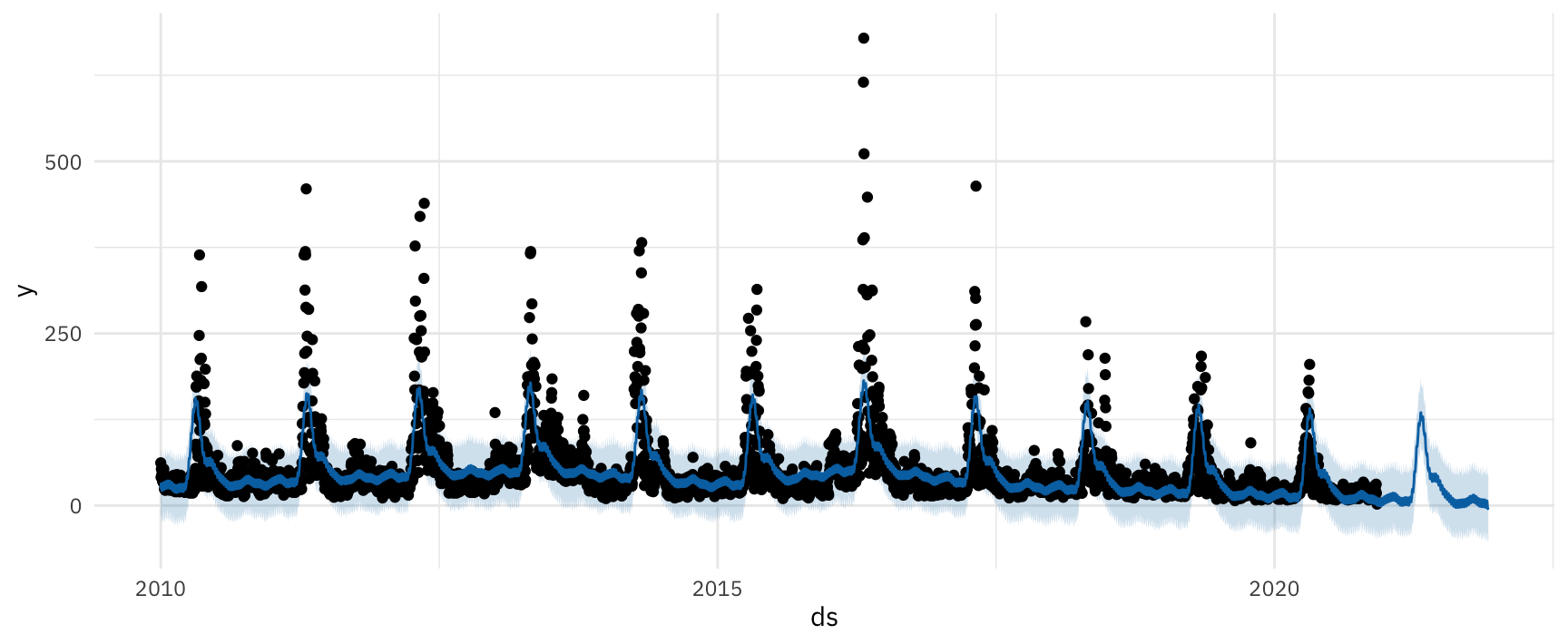
Рисунок 9: Визуализация прогноза по количеству пожаров в Красноярском крае на 2021 год в библиотеке Prophet
Рассмотрим компоненты разложения временного ряда.
prophet_plot_components(m, forecast)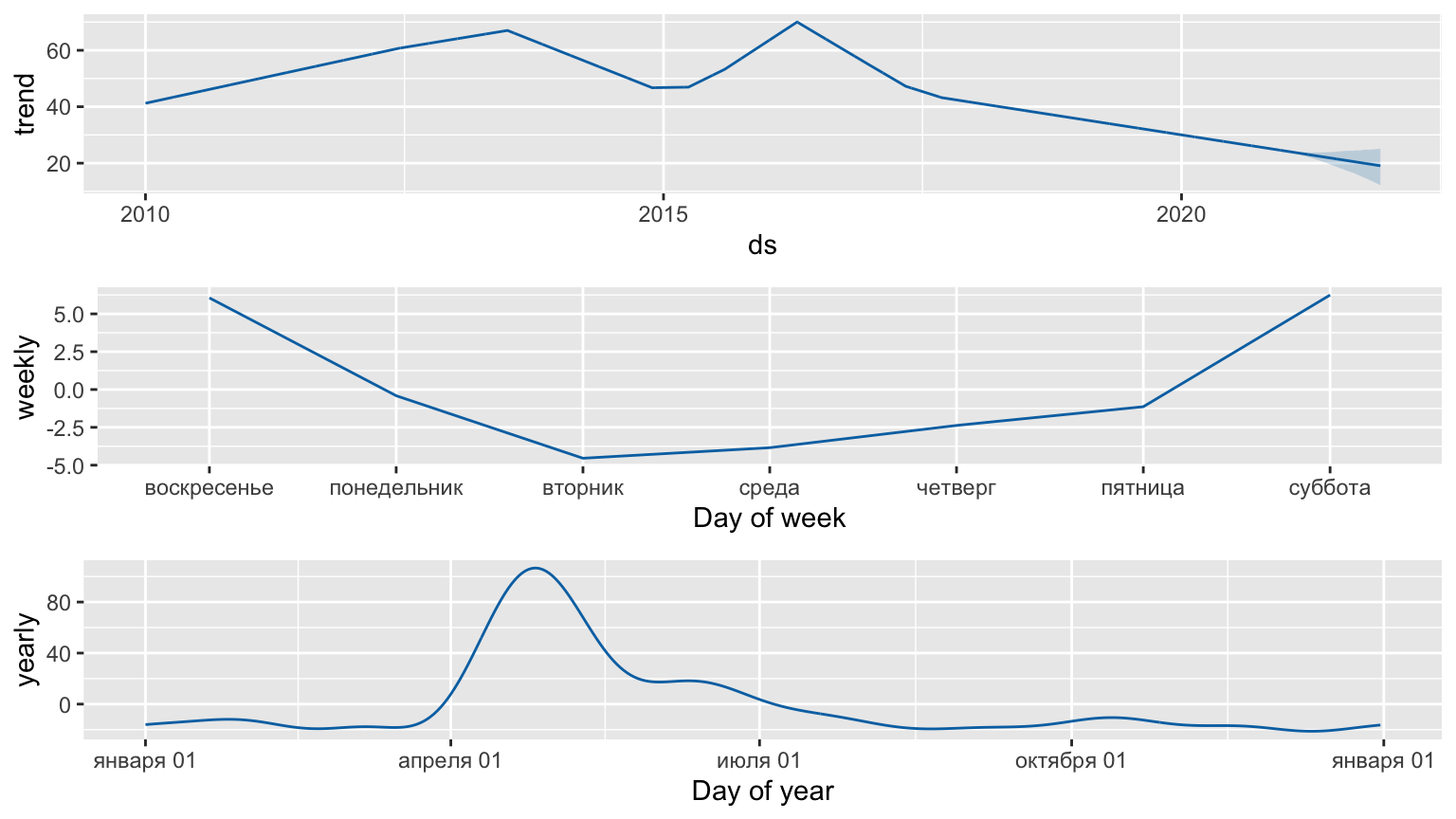
Рисунок 10: Компоненты разложения временного ряда в библиотеке Prophet
Из графика видно, что
- в последние годы наблюдается небольшое снижение тренда;
- наименьшее количество пожаров происходило по вторникам, наибольшее – в выходные дни;
- ежегодный всплеск количества пожаров приходится на конец апреля – начало июля.
Рассмотрим точки изменения тренда.
plot(m, forecast) + add_changepoints_to_plot(m)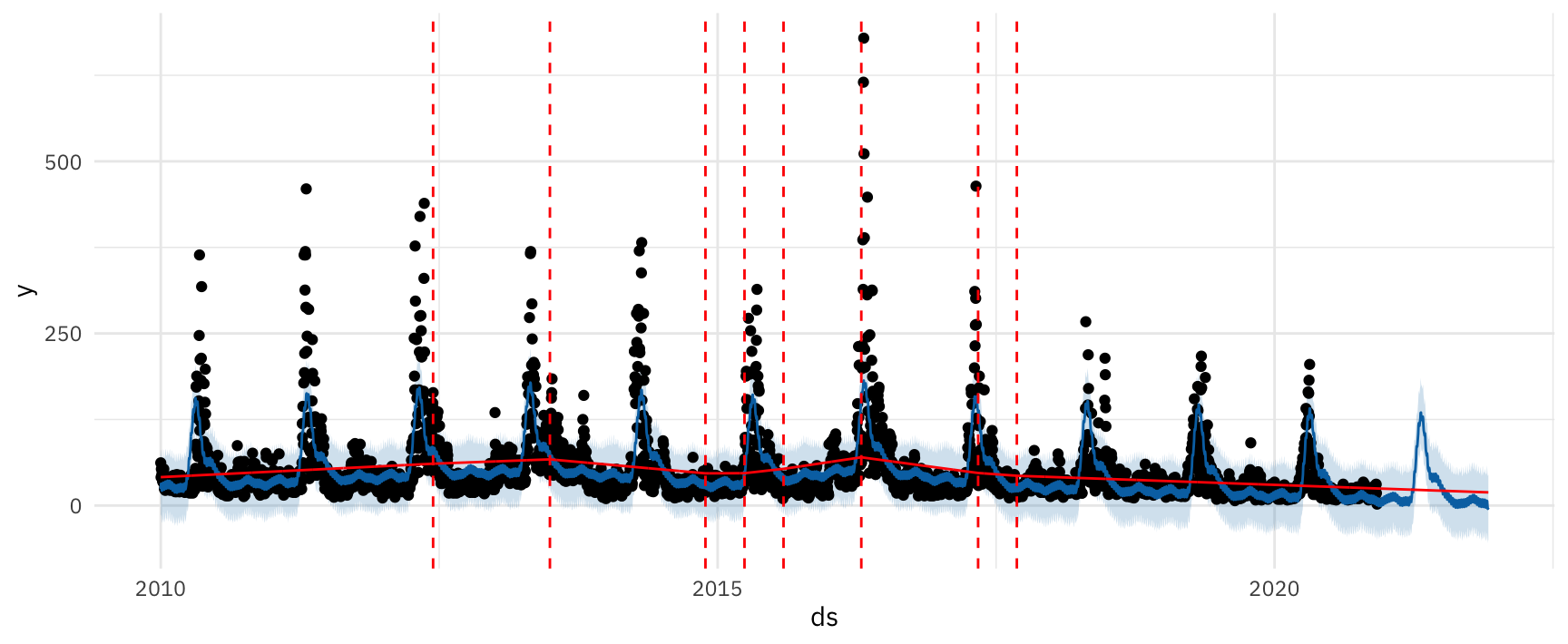
Рисунок 11: Точки изменения тренда в библиотеке Prophet
Аномалии
Для работы аномалиями нам понадобятся библиотеки tibbletime и anomalize.
Отметим различие характера аномалий в первые и последние года исследования. В первые три года аномалии начинаются с середины тренда, в то время как в последние года смещаются к его пику. Возможно, данная тенденция может быть связана с климатическими изменениями.
library(tibbletime)
library(anomalize)
pozh_df %>% select(-f2) %>%
filter(f5 <= as.Date("2012-12-30")) %>%
count(., f5, name = "count") %>%
as_tbl_time(., f5) %>%
ungroup() %>%
time_decompose(count) %>%
anomalize(remainder) %>%
plot_anomaly_decomposition() +
labs(title = "STL-декомпозиция аномалий",
subtitle = "с 2010 по 2012 год",
x = "", y = "") +
scale_x_date(date_breaks = "12 months",
date_labels = "%Y")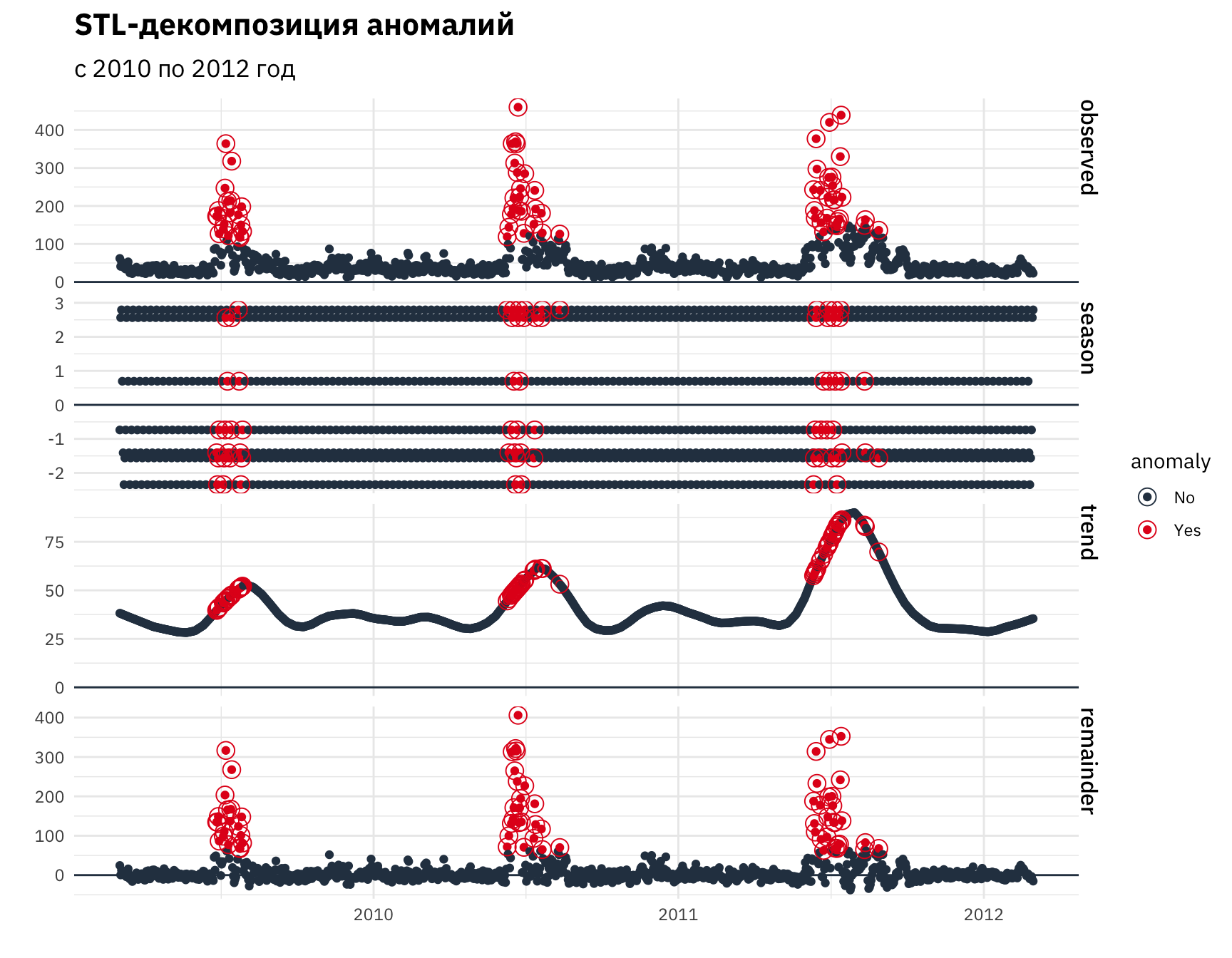
Рисунок 12: Аномалии временного ряда (период с 2010 по 2012 год)
Аномалии временного ряда за последние три года.
pozh_df %>% select(-f2) %>%
filter(f5 >= as.Date("2017-12-30")) %>%
count(., f5, name = "count") %>%
as_tbl_time(., f5) %>%
ungroup() %>%
time_decompose(count) %>%
anomalize(remainder) %>%
plot_anomaly_decomposition() +
labs(title = "STL-декомпозиция аномалий",
subtitle = "с 2018 по 2020 год",
x = "", y = "") +
scale_x_date(date_breaks = "12 months",
date_labels = "%Y") 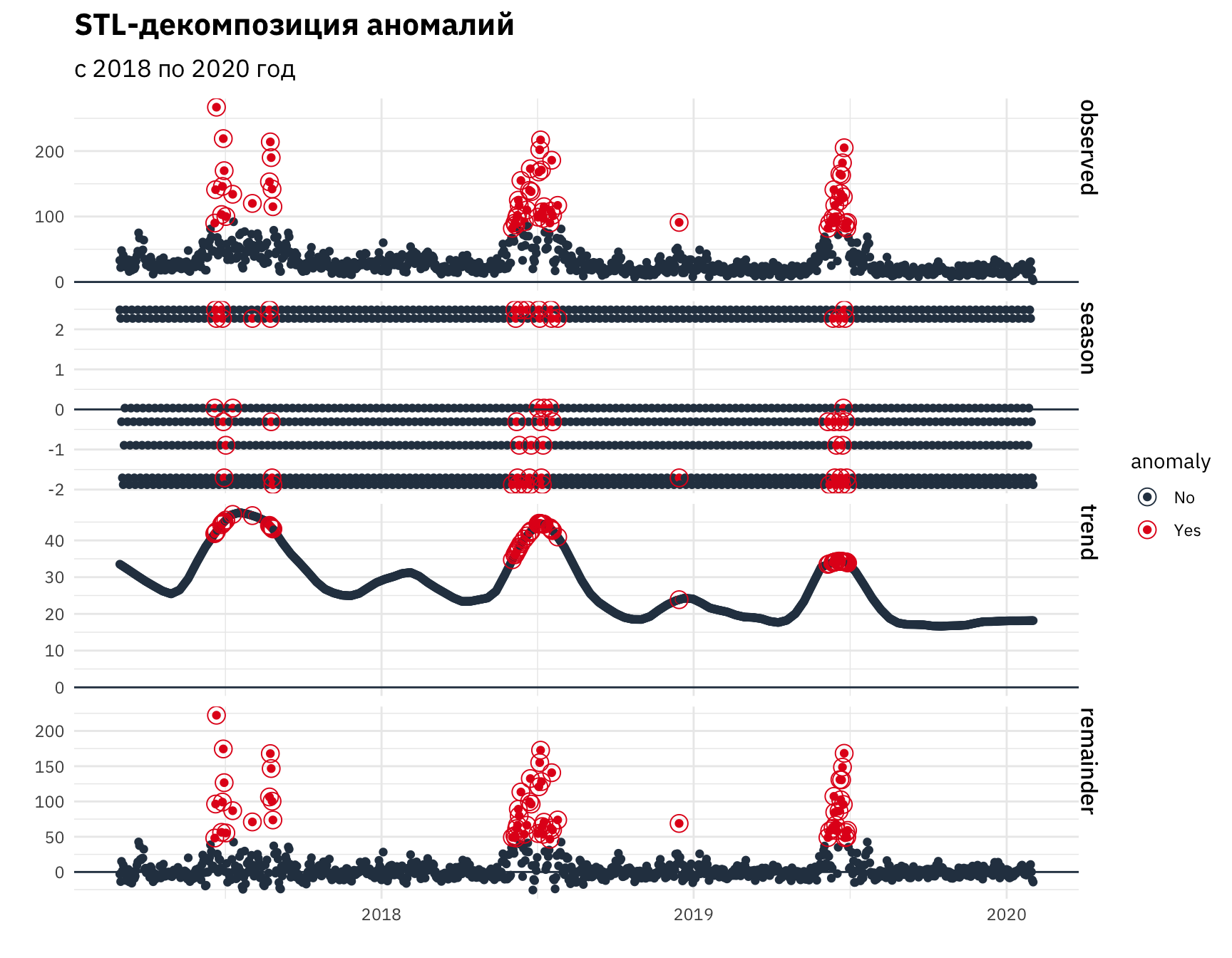
Рисунок 13: Аномалии временного ряда (период с 2018 по 2020 год)
Заключение
Мы кратко рассмотрели данные по пожарам в Красноярском крае за период, охватывающий последние 10 лет. Данным был сопоставлен временной ряд. Мы увидели пропуски в заполнении исходных данных, рассмотрели периодические компоненты, тренд и аномалии. Можно отметить следующие предварительные выводы:
- некоторый объем данных потерян, для корректной работы следует заполнить соответствующие пропущенные значения2;
- в последние годы наблюдается тренд на снижение количества пожаров в Красноярском крае;
- больше всего пожаров происходит в выходные дни;
- аномальные всплески количества пожаров наблюдаются примерно с конца апреля по июнь;
- характер аномалий в первые и последние годы исследования изменился.
Евгений Матеров
Зав. кафедрой физики, математики и информационных технологий
Область моих научных интересов включает в себя Data Science, машинное обучение, язык программирования R.