Прогнозирование гибели на пожарах на основе алгоритма бэггинга
использование библиотеки tidymodels в задаче о классификации
В языке R существует множество различных библиотек для работы с алгоритмами машинного обучения. Это и mlr3 и caret, однако в последнее время большое развитие получила мета-библиотека tidymodels, использующая современный подход с использованием принципов tidyverse.
Фреймворк tidymodels представляет собой интегрированный, модульный, расширяемый набор библиотек, облегчающий создание предикативных стохастических моделей на основе принципов машинного обучения. Эти библиотеки придерживаются принципов синтаксиса и дизайна tidyverse, что способствует согласованности при пошаговом написании кода. Они автоматически строят параллельное выполнение для таких задач, как повторная выборка, перекрестная проверка и настройка параметров. Более того, библиотеки tidymodels не просто прорабатывают этапы базового рабочего процесса моделирования, они реализуют концептуальные структуры, которые делают сложные итерационные рабочие процессы возможными и воспроизводимыми. Мы используем подход Julia Silge для моделирования признака гибели на пожарах с помощью алгоритма бэггинга.
Установка библиотеки
Стабильную версию библиотеки можно установить из репозитория CRAN:
install.packages("tidymodels")Девелоперская версия доступна на GitHub:
devtools::install_github("tidymodels/tidymodels")Вот некоторые основные библиотеки, входящие в ядро tidymodels:
broom– приводит вывод встроенных функций R в опрятный (tidy) вид фрейма данных;parnip– инерфейс для создания моделей;recipes– это общий препроцессор данных с современным интерфейсом, который может создавать матрицы моделей, включающие в себя проектирование объектов и другие вспомогательные инструменты;rsample– имеет инфраструктуру для повторной выборки данных, чтобы модели могли быть оценены и эмпирически подтверждены;tune– содержит функции оптимизации гиперпараметров модели;workflows– содержит методы для объединения этапов предварительной обработки и моделей в единый объект;yardstick– содержит инструменты для оценки моделей.
На сайте tidymodels представлено хорошее введение в библиотеку, кроме того, работе с tidymodels посвящена книга [Kuhn & Silge], а также блог Julia Silge.
Исходные данные
Подключим необходимые библиотеки.
library(tidyverse)
library(magrittr)
library(themis)Данные, которые используются в этой статье, представляют собой электронные карточки учета пожаров1 по пожарам в Красноярском крае в 2019 году2.
library(RCurl)
GitHubURL <- "https://raw.githubusercontent.com/materov/blog_data/main/data_fire.csv"
fire <- readr::read_csv(GitHubURL)
fire <-
fire %>%
mutate_if(is.character, factor) %>%
mutate_if(is.numeric, as.integer)Строки таблицы данных соответствуют одному наблюдению, а переменные-столбцы – поля карточки учета пожаров.
fire## # A tibble: 12,477 x 45
## X1 F1 F2 F3 F4 F5 F6 F7 F8 F9 F10 F11
## <int> <fct> <fct> <int> <fct> <date> <fct> <fct> <fct> <fct> <fct> <fct>
## 1 1 Красн… Крас… 1869 осно… 2019-07-12 Город ГПС:… Муни… Унит… орга… Жило…
## 2 2 Красн… Крас… 1870 осно… 2019-06-29 Город ГПС:… Част… форм… орга… Жило…
## 3 3 Красн… Крас… 1871 осно… 2019-07-12 Город ГПС:… Муни… Унит… орга… Проч…
## 4 4 Красн… Крас… 1872 осно… 2019-07-12 Город ГПС:… Муни… Унит… орга… Проч…
## 5 5 Красн… Крас… 1873 осно… 2019-07-13 Город ГПС:… Муни… Унит… орга… Проч…
## 6 6 Красн… Крас… 1874 осно… 2019-07-13 Город ГПС:… Муни… Унит… орга… Проч…
## 7 7 Красн… Крас… 1875 осно… 2019-07-13 Город ГПС:… Муни… Унит… орга… Проч…
## 8 8 Красн… Крас… 1876 осно… 2019-07-13 Город ГПС:… Муни… Унит… орга… Проч…
## 9 9 Красн… Крас… 1877 осно… 2019-07-13 Город ГПС:… Част… форм… орга… Вид …
## 10 10 Красн… Крас… 1878 осно… 2019-07-13 Город ГПС:… Муни… Унит… орга… Проч…
## # … with 12,467 more rows, and 33 more variables: F12 <fct>, F13 <fct>,
## # F14 <int>, F15 <int>, F16 <fct>, F17 <fct>, F17A <fct>, F18 <fct>,
## # F19 <fct>, F20 <fct>, F21 <fct>, F22 <fct>, F23 <int>, F27 <int>,
## # F28 <int>, F29 <int>, F30 <int>, F31 <int>, F32 <int>, F56 <int>,
## # F75 <fct>, F112 <int>, F113 <int>, F114 <int>, F115 <int>, F116 <int>,
## # F78 <fct>, F79 <fct>, F80 <fct>, F81 <fct>, F82 <fct>, F148 <fct>,
## # F149 <fct>Например, заголовок F12 отвечает за вид объекта пожара, F17 – место возникновения пожара, F27 – количество погибших на пожаре, и т.д. Удалим из рассмотрения некоторые строки, относящиеся к горению мусора.
# исключаемые категории вида объекта пожара
F12_exclude <- c("Сухая трава (сено, камыш и т.д.)",
"Мусор вне территории жилой зоны и предприятия, организации, учреждения",
"Мусор на территории жилой зоны (кроме территории домовладения)")
# исключаемые категории места возникновения пожара
F17_exclude <- c("Полоса отчуждения, обочина дороги, луг, пустырь",
"Прочее место на открытой территории",
"Площадка для мусора на территории жилой зоны")
'%!in%' <- function(x,y)!('%in%'(x,y))
fire <- fire %>%
filter(F12 %!in% F12_exclude,
F17 %!in% F17_exclude)Действительно, можно показать, что к указанным выше категориям не относится ни одного случая гибели, что не должно существенно повлиять на результат для нашей модели. Создадим новую переменную died_cases для классификации погибших.
fire <- fire %>% mutate(
died_cases = case_when(F27 > 0 ~ "died",
TRUE ~ "not_died")
)
fire <- fire %>% select(-F27)Следующая таблица показывает процент погибших на пожарах.
fire %>%
janitor::tabyl(died_cases) %>%
janitor::adorn_pct_formatting(digits = 1) %>%
purrr::set_names("категория", "количество", "процент")## категория количество процент
## died 172 3.1%
## not_died 5395 96.9%Изменение процента гибели с течением времени можно оценить следующим образом.
fire %>%
mutate(fire_date = lubridate::floor_date(F5, unit = "week")) %>%
count(fire_date, died_cases) %>%
group_by(fire_date) %>%
mutate(percent_died = n / sum(n)) %>%
ungroup() %>%
filter(died_cases == "died") %>%
ggplot(aes(fire_date, percent_died)) +
geom_line(size = 1, alpha = 0.7, color = "midnightblue") +
scale_y_continuous(limits = c(0, NA),
labels = scales::percent_format()) +
labs(x = NULL, y = "процент пожаров с гибелью людей\n")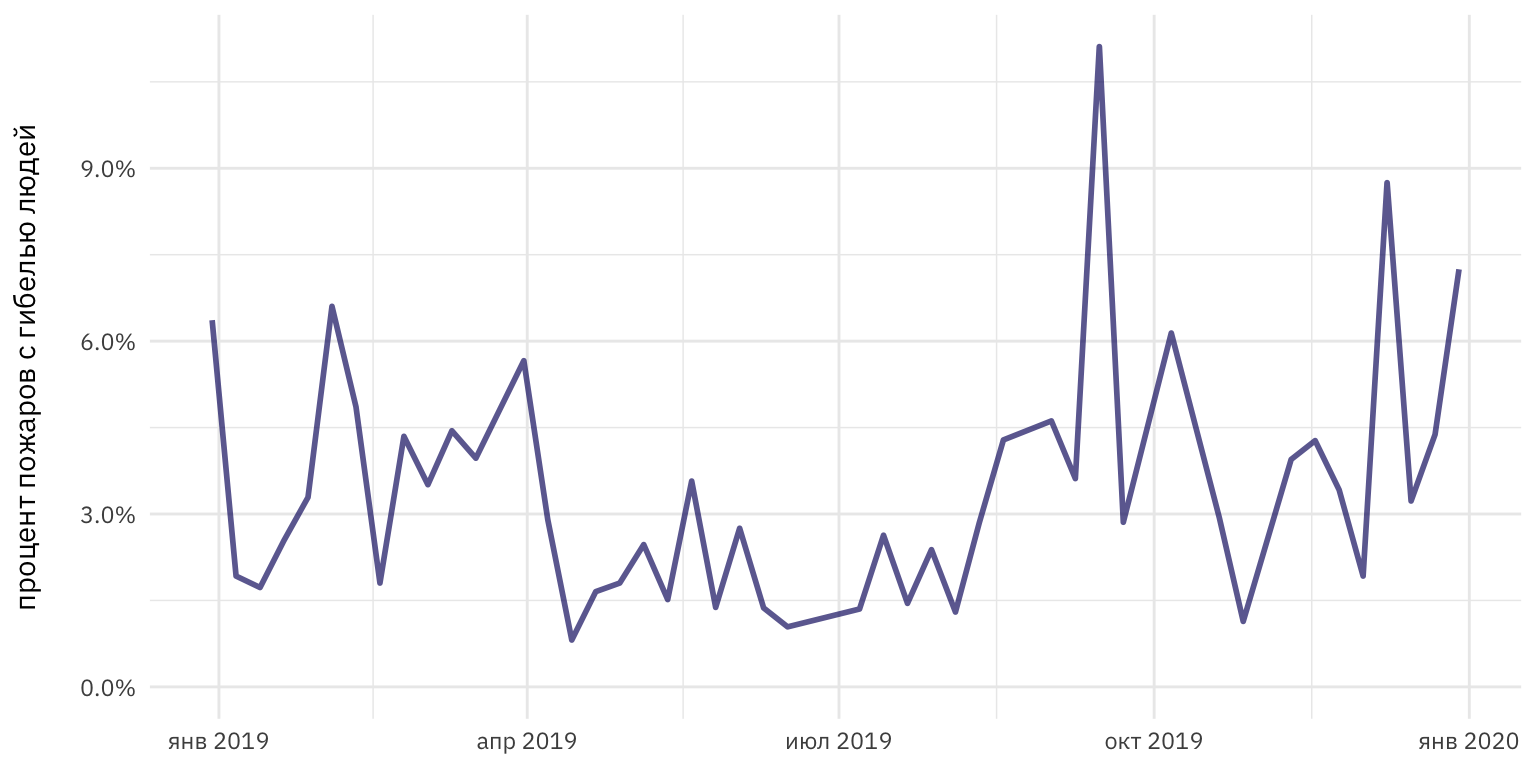
Рисунок 1: Изменение процента гибели людей на пожарах
Выберем переменные, которые войдут в нашу модель кроме классифицирующей переменной:
fire <- fire %>% select(F5, F6, F12, F17, F17A, F18, F19, F22, died_cases)| имя | значение |
|---|---|
| F5 | дата пожара |
| F6 | вид населенного пункта |
| F12 | вид объекта пожара |
| F17 | место возникновения пожара |
| F17A | строительная конструкция (конструктивный элемент) |
| F18 | изделие, устройство (источник зажигания, от которого непосредственно возник пожар) |
| F19 | причина пожара |
| F22 | состояние виновника пожара |
Построение модели
Начнем с разделения данных на обучающую и тестовую выборки и стратификации для перекрестной проверки.
library(tidymodels)
set.seed(123)
fire_split <- initial_split(fire, strata = died_cases)
fire_train <- training(fire_split)
fire_test <- testing(fire_split)
set.seed(123)
fire_folds <- vfold_cv(fire_train, strata = died_cases)
fire_folds## # 10-fold cross-validation using stratification
## # A tibble: 10 x 2
## splits id
## <list> <chr>
## 1 <split [3758/418]> Fold01
## 2 <split [3758/418]> Fold02
## 3 <split [3758/418]> Fold03
## 4 <split [3758/418]> Fold04
## 5 <split [3758/418]> Fold05
## 6 <split [3758/418]> Fold06
## 7 <split [3759/417]> Fold07
## 8 <split [3759/417]> Fold08
## 9 <split [3759/417]> Fold09
## 10 <split [3759/417]> Fold10Теперь построим модель используя процедуру бэггинга (сокр. от bootstrap aggregating). Идея бэггинга хорошо описана в книге [Шитиков В. К., Мастицкий С. Э.]: мы строим деревья решений по обучающим бутсреп-выборкам и дальнейшем усреднении коллективного прогноза, что позволяет уменьшить дисперсию прогноза.
Мы создадим рецепт, в который войдут:
- базовая формула, показывающая что
died_casesбудет зависеть от всех остальных переменных; - создание определяющих параметров, начинающихся с
step_*(), в частности, для переменной даты, номинальных переменных и понижающей дискретизацииstep_downsample()для учета классового дисбаланса (процент гибели, как мы видели, невысок).
fire_rec <- recipe(died_cases ~ ., data = fire) %>%
step_date(F5) %>%
step_rm(F5) %>%
step_dummy(all_nominal(), -died_cases) %>%
step_downsample(died_cases)Следующий шаг – непосредственное определение модели (здесь bagging tree).
bag_spec <- baguette::bag_tree(min_n = 10) %>%
set_engine("rpart", times = 20) %>%
set_mode("classification")Для бинарной классификации можно использовать и другие модели, например, как на странице библиотеки
parsnip.
Рабочий процесс – это объект, который может объединять запросы предварительной обработки, моделирования и последующей обработки. Преимущества рабочего процесса заключаются в следующем:
- Вам не нужно следить за отдельными объектами в вашем рабочем пространстве.
- Подготовка рецепта и подгонка модели могут быть выполнены с помощью одного вызова функции
fit(). - Если у вас есть пользовательские настройки параметров настройки, они могут быть определены с помощью более простого интерфейса в сочетании с настройкой.
- В рабочие процессы можно добавлять операции постобработки, такие как изменение отсечки вероятности для моделей двух классов.
fire_wf <- workflow() %>%
add_recipe(fire_rec) %>%
add_model(bag_spec)
fire_wf## ══ Workflow ════════════════════════════════════════════════════════════════════
## Preprocessor: Recipe
## Model: bag_tree()
##
## ── Preprocessor ────────────────────────────────────────────────────────────────
## 4 Recipe Steps
##
## ● step_date()
## ● step_rm()
## ● step_dummy()
## ● step_downsample()
##
## ── Model ───────────────────────────────────────────────────────────────────────
## Bagged Decision Tree Model Specification (classification)
##
## Main Arguments:
## cost_complexity = 0
## min_n = 10
##
## Engine-Specific Arguments:
## times = 20
##
## Computational engine: rpartТеперь проверим эту модель на повторных выборках перекрестной проверки, чтобы понять, насколько хорошо она будет работать.
doParallel::registerDoParallel()
fire_res <- fit_resamples(
fire_wf,
fire_folds,
control = control_resamples(save_pred = TRUE)
)Оценка модели
Для оценки производительности модели служит функция metrics(), информация которая важна для нас, – показатель ROC AUC (чем ближе к 1, тем лучше):
collect_metrics(fire_res)## # A tibble: 2 x 6
## .metric .estimator mean n std_err .config
## <chr> <chr> <dbl> <int> <dbl> <fct>
## 1 accuracy binary 0.748 10 0.00772 Preprocessor1_Model1
## 2 roc_auc binary 0.800 10 0.0163 Preprocessor1_Model1После обзора предварительной оценки модели, мы подгоним модель, распространив ее на все обучающее множество и рассмотрим значения на тестовом множестве.
fire_fit <- last_fit(fire_wf, fire_split)
collect_metrics(fire_fit)## # A tibble: 2 x 4
## .metric .estimator .estimate .config
## <chr> <chr> <dbl> <fct>
## 1 accuracy binary 0.735 Preprocessor1_Model1
## 2 roc_auc binary 0.840 Preprocessor1_Model1Произведем оценку значимости признаков.
fire_imp <- fire_fit$.workflow[[1]] %>%
pull_workflow_fit()
fire_imp$fit$imp %>%
slice_max(value, n = 7) %>%
ggplot(aes(value, fct_reorder(term, value))) +
geom_col(alpha = 0.8, fill = "midnightblue") +
labs(x = "\nОценка важности признаков", y = NULL)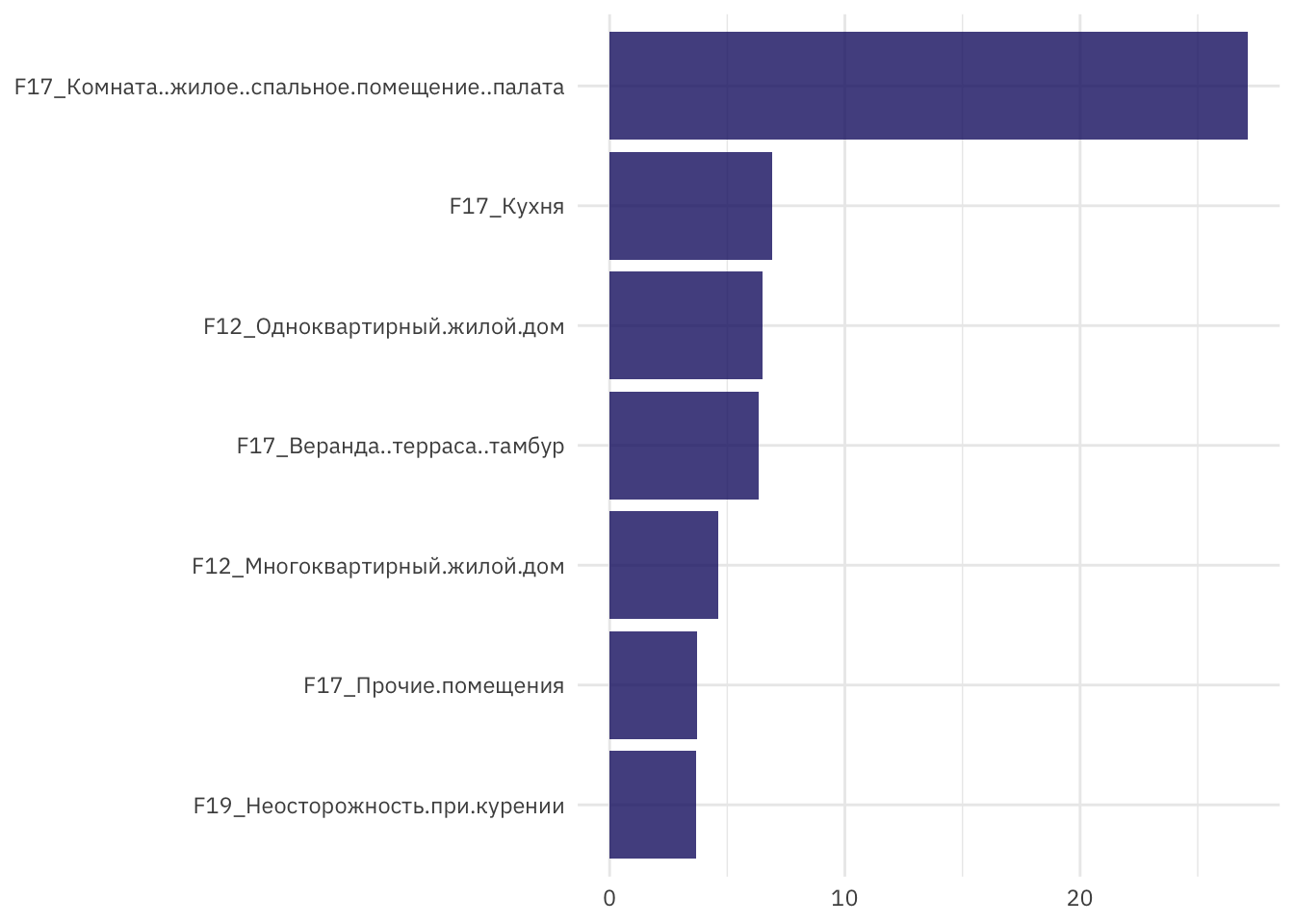
Рисунок 2: Оценка важности признаков
Построим ROC кривую для оценки модели.
fire_fit %>%
collect_predictions() %>%
roc_curve(died_cases, .pred_died) %>%
ggplot(aes(x = 1 - specificity, y = sensitivity)) +
geom_line(size = 1.5, color = "midnightblue") +
geom_abline(
lty = 2,
alpha = 0.5,
color = "gray50",
size = 1.2
) +
coord_equal()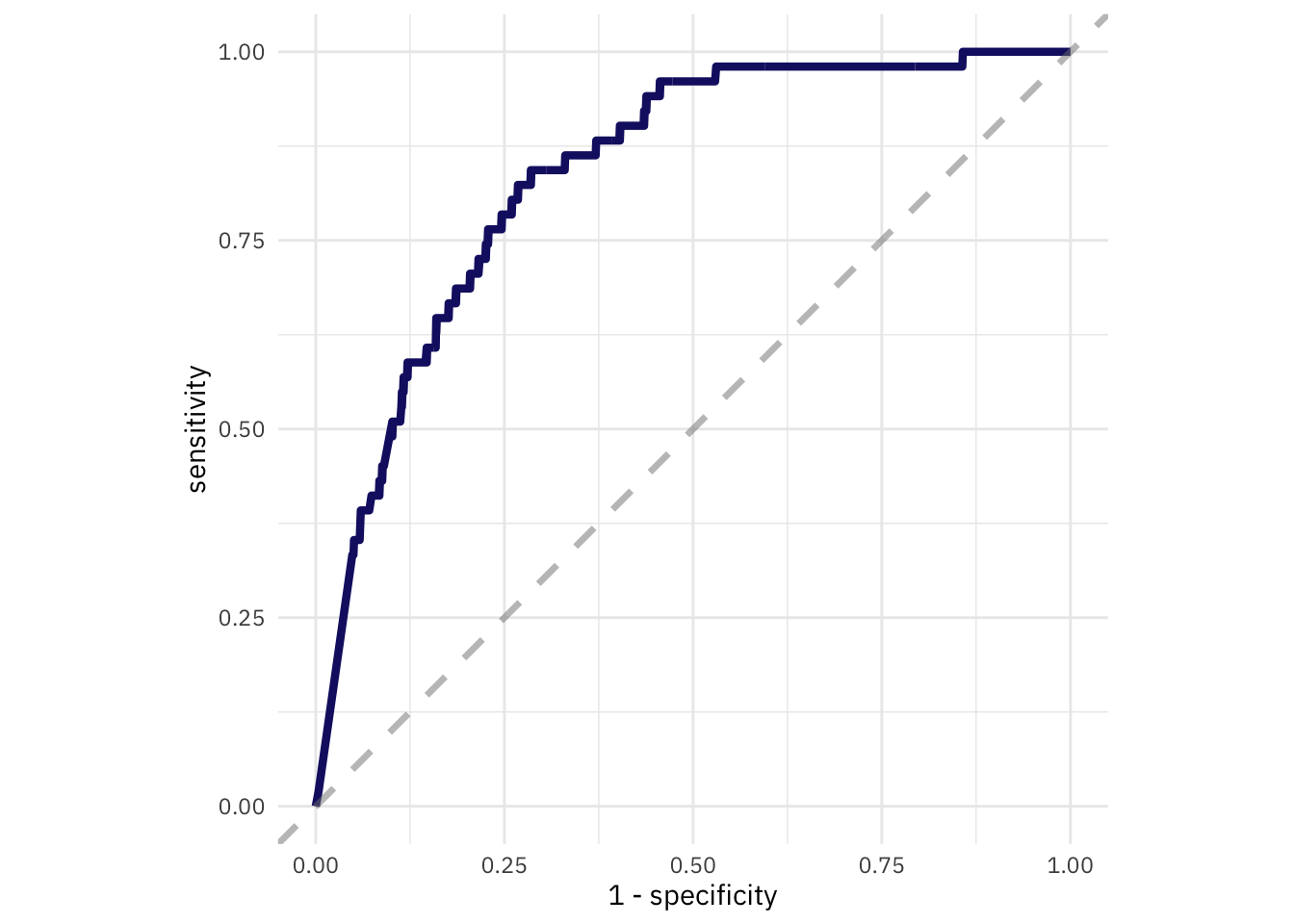
Рисунок 3: ROC-кривая модели
Заключение
Мы рассмотрели простейшую модель для определения погибших на пожаре, определили наиболее важные ее параметры и оценили с помощью ROC-кривой. Кроме того, мы рассмотрели основные принципы построения моделей в tidymodels.
Приказ МЧС России от 24 декабря 2018 № 625 О формировании электронных баз данных учета пожаров и их последствий.↩︎
Автор выражает благодарность В.В. Ничепорчуку за предоставленные данные.↩︎
Евгений Матеров
Зав. кафедрой физики, математики и информационных технологий
Область моих научных интересов включает в себя Data Science, машинное обучение, язык программирования R.